TIL(11월)
틀린 내용이나 본문의 내용과 다른 의견이 있으시면 댓글로 남겨주세요!
11/28
- SPA - 템플릿은 그대로 두고 데이터만 갈아끼운다.
Vue에서 <style scoped>는 웬만하면 달아준다. 스타일의 범위를 해당 뷰 파일로 한정짓는다. 글로벌하게 먹이고 싶은 스타일은 app.vue 에다가 scoped 없이 하자.
온갖 .vue 파일을 브라우저가 알 수 있는 형태로 변환시켜서 index.html, js, css로 내보내준다.
vue 파일에서 template 태그 바로 아래에 어떤 태그가 두개가 같은 라인에 있으면 안된다.
11/25
- ContextLoaderListener
Spring의 ContextLoaderListener가 아닌, DI미션 중 ContextLoaderListener를 기준으로 알아본다.
@WebListener
public class ContextLoaderListener implements ServletContextListener
위와 같은 식으로 선언 되어있다.
하나씩 살펴보면 @WebListener는 웹 어플리케이션 컨텍스트의 다양한 형태의 이벤트 리스너를 선언하기 위해 사용된다.
- javax.servlet.http.HttpSessionAttributeListener
- javax.servlet.http.HttpSessionListener
- javax.servlet.ServletContextAttributeListener
- javax.servlet.ServletContextListener
- javax.servlet.ServletRequestAttributeListener
- javax.servlet.ServletRequestListener
- javax.servlet.http.HttpSessionIdListener
이 어노테이션이 붙은 클래스는 위의 인터페이스 중 한 가지 이상을 반드시 구현해야 한다. 그래서 DI 미션의 ContextLoaderListener는 ServletContextListener를 구현하고 있다.
ServletContextListener를 살펴보면 이 인터페이스의 구현체(여기서는 ContextLoaderListener)는 웹 어플리케이션의 servlet context의 변화에 대한 알림을 받는다. 알림 이벤트를 받기 위해 구현체 클래스는 웹 어플리케이션의 web.xml(deployment descriptor)에 설정되어있어야 한다.
public void contextInitialized(ServletContextEvent sce);는 웹 어플리케이션 초기화 과정이 시작한다는 알림이다. 어떤 필터나 서블릿도 초기화 되기 전에 컨텍스트의 초기화에 대한 알림을 받는다.
public void contextDestroyed(ServletContextEvent sce);는 서블릿 컨텍스트가 끝날 때의 알림이다. 모든 ServletContextListener가 종료 알림을 받기 전에 모든 서블릿과 필터들은 destroy된다.
ContextLoaderListener는 선택사항이다. Spring application을 ContextLoaderListener를 설정하는 것 없이 최소의 web.xml의 DispatcherServlet만으로 구동시킬 수 있다.
더 복잡한 스프링 어플리케이션에서는 여러개의 DispatcherSerlvet을 가질 수 있다. 그리고 모든 DispatcherServlet에서 공유하는 공통의 ContextLoaderListener에 정의 된 스프링 설정 파일을 가질 수 있다.
ContextLoaderListener는 root application context의 실제 초기화를 수행한다는 것만 생각하면 된다.
11/23
ComponentScan
- 스프링은 어노테이션 컴포넌트들을 스캔하기 위한 패키지를 알 필요가 있다.(IoC 컨테이너에 추가하기 위해서) 스프링부트에서는 보통 @SpringBootApplication을 볼 수 있다. 이 안에 들어가보면 @Configuration, @ComponentScan, @EnableAutoConfiguration 이런 어노테이션들이 달려있다. 이런 기본 설정과 함께 스프링부트는 현재 패키지 안의 컴포넌트들을 스캔한다.(스프링부트 메인 클래스를 포함하는 패키지와 그 하위 패키지들)
- @ComponentScan 어노테이션은 어노테이션 달려있는 컴포넌트들을 스캔할 패키지를 스프링에게 알려주기 위해 @Configuration 어노테이션과 함께 쓰인다. @ComponentScan은 basePackages 또는 basePackageClasses attribute를 이용해서 베이스 패키지를 정한다.
- 여기서 basePackageClasses는 type safe한 basePackages다.
- 스프링이 제공하는 다른 타입의 필터를 사용해서 컴포넌트 스캔을 설정할 수 있다.
- 필터를 사용해서 베이스 패키지 내에 있는 모든 것들로부터 후보를 좀 좁힐 수 있다. (필터에 맞는 애들로)
- 필터는 include, exclude 필터가 있다. (이름이 말해주는 그대로 동작한다.)
- default filter를 없애려면 useDefaultFilters를 false로 한다.
@ComponentScan(useDefaultFilters = false) - FilterType은 다음과 같다.
- FilterType.ANNOTATION: stereotype 어노테이션 달려있는 클래스들을 포함, 제외
- FilterType.ASPECTJ: AspectJ 타입 패턴 표현을 사용한 클래스 포함, 제외
- FilterType.ASSIGNABLE_TYPE: 이 클래스나 인터페이스를 extend, implement 하는 클래스들을 포함, 제외
- FilterType.REGEX: 정규표현식 사용해서 클래스 포함, 제외
- FilterType.CUSTOM: TypeFilter 인터페이스를 implement 해서 커스텀으로 만든 필터 사용해서 클래스들을 포함, 제외
- @SpringBootApplication 어노테이션은
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class), @Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })를 가지고 있다.- 살펴보면 TypeExcludeFilter, AutoConfigurationExcludeFilter를 제외한다.
- TypeExcludeFilter는 주석을 살펴보면, 잘 모르겠다. spring-boot-test를 위해 주로 사용된다고 한다.
- AutoConfigurationExcludeFilter의 match 메서드를 살펴보면
return isConfiguration(metadataReader) && isAutoConfiguration(metadataReader);라고 되어있는데 AutoConfiguration이면서 Configuration 어노테이션이 달려있는 클래스면 match method가 true가 되어서 ComponentScan에서 제외된다.
- 살펴보면 TypeExcludeFilter, AutoConfigurationExcludeFilter를 제외한다.
11/20
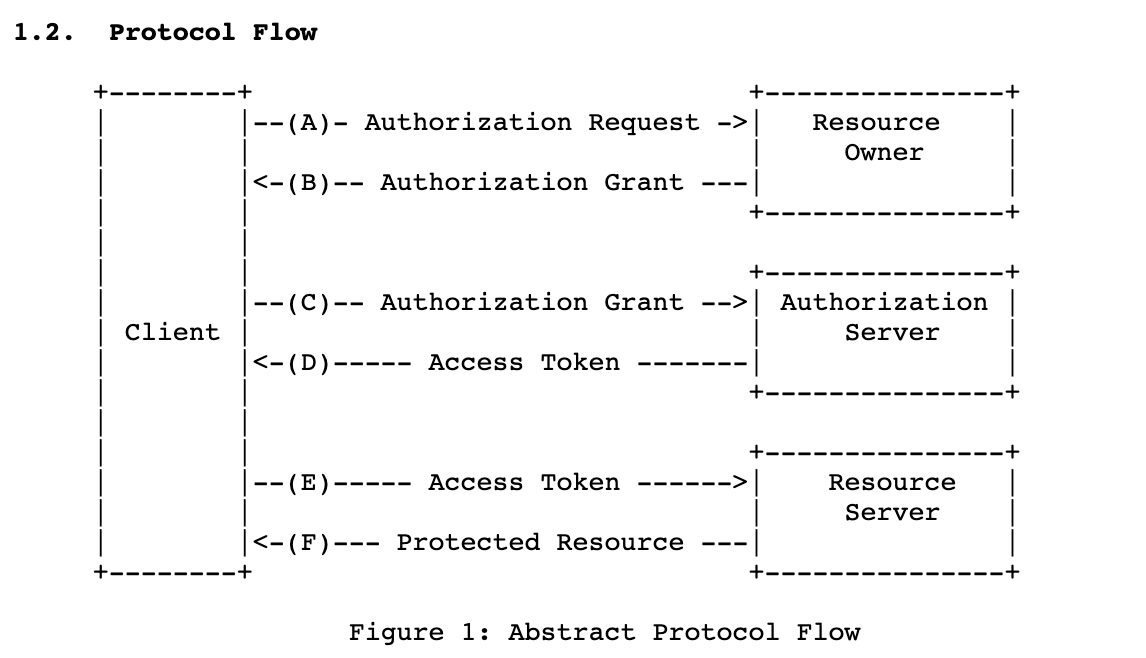
- OAuth 2.0
- OAuth 1에 비해 인증 절차가 간소화 됨
- 암호화는 https에 맡김 (디지털 서명 로직이 필요 없어짐)
- 내 서버가 Client, 내 서버를 이용하는 것이 Resource Owner, Github 서버가 Resource Server(Authorization server)
- 다양한 인증 방식
- Authorization Code Grant
- Implicit Grant
- Resource Owner Password Credentials Grant
- Client Credentials Grant
- Device Code Grant
- Refresh Token Grant
- Authorization Code Grant
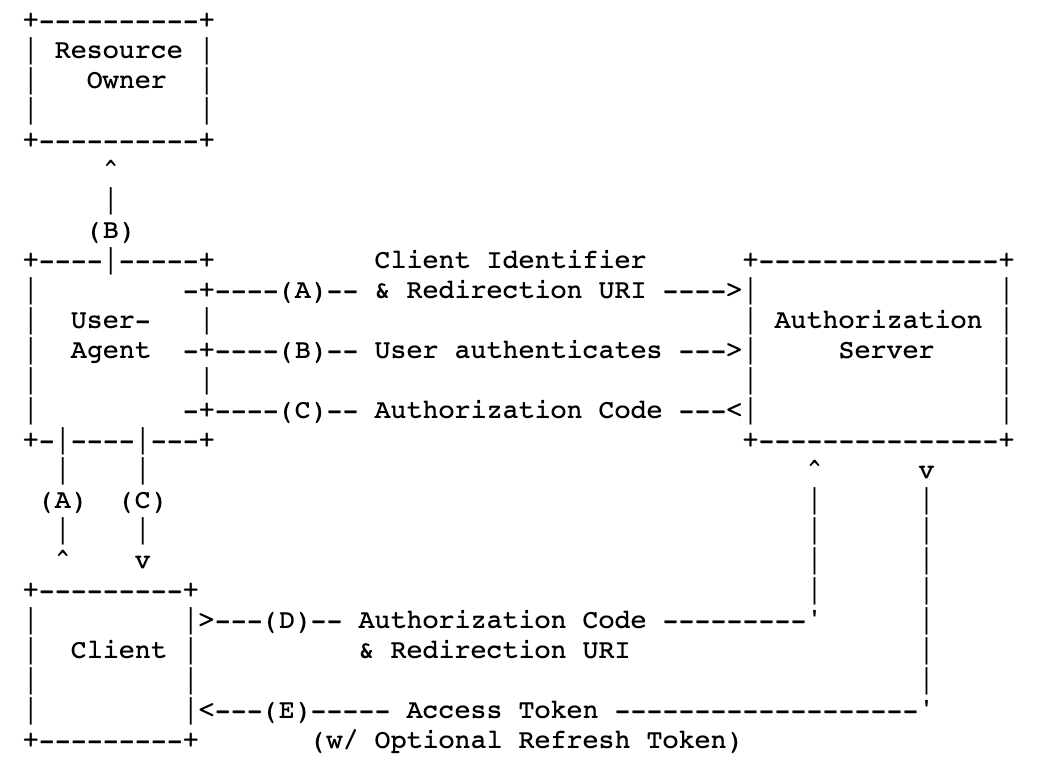
- Access Token과 Refresh Token을 둘다 얻으려고 할 때 사용된다.
- 클라이언트가 Authorization server에 인증 요청을 한다. (Redirect URL 포함)
- Authorization Server는 유저에게 로그인창을 띄움(Github으로 로그인~ 이런 것)
- Authorization Server는 인증 코드를 클라이언트에게 제공
- 클라이언트는 인증 코드로 Authorization Server에 Access Token을 요청한다.
- Authorization Server는 클라이언트에 Access Token을 발급한다.
- Access Token을 이용하여 Resource Server의 자원을 접근할 수 있게 된다.
- 토큰이 만료되면 refresh token을 이용해 토큰을 재발급 받는다.
- Implicit Grant
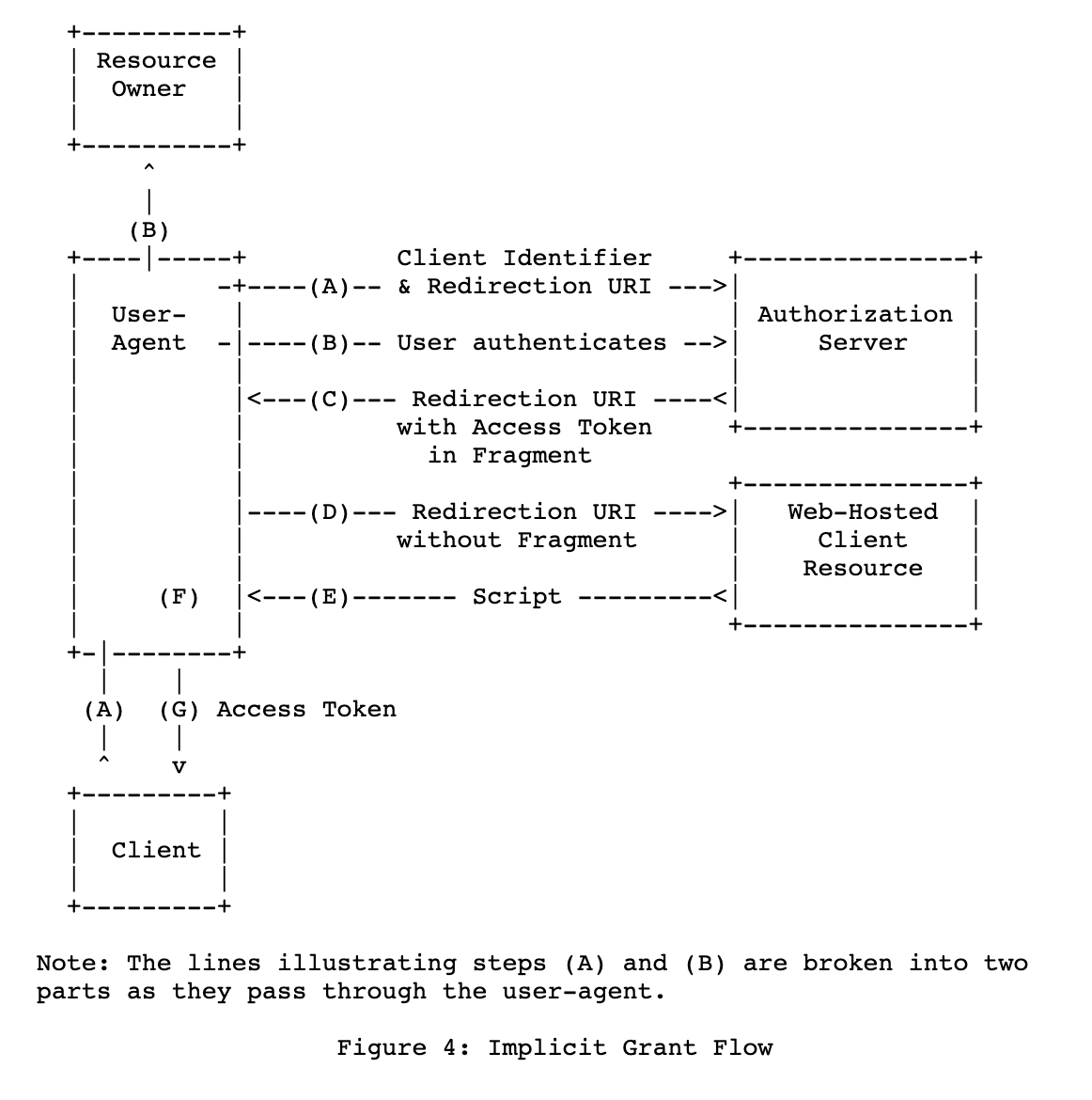
- 클라이언트가 Authorization server에 인증 요청
- 유저는 Authorizatiojn server를 통해 인증
- Authorization server는 Access token을 포함하여 클라이언트의 Redirect url 호출
- 클라이언트는 Access token이 유효한지 Authorization server에 인증 요청
- Authorization server는 토큰이 유효하면 토큰의 expired time과 함께 리턴
- 클라이언트는 Resource server의 자원을 접근할 수 있게 된다.
- OAuth 1에 비해 인증 절차가 간소화 됨
참고자료(OAuth)
11/18
- 자바의 String
Object의 toString() 메서드는 왜 하위 객체인 String을 return 할까 라는 생각에서 출발해서 뜬금없이 String의 intern() 메서드를 알아본다.
일단 Object의 toString()은 자바 문서에 Returns a string representation of the object. In general, the toString method returns a string that "textually represents" this object. The result should be a concise but informative representation that is easy for a person to read. It is recommended that all subclasses override this method. 라고 나와있다. 그러나 왜, 어떻게 부모 객체인 Object에서 자식 객체인 String을 사용하게 됬는지..는 알 수 없었다.
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
대충 읽어보면 String pool에 들어있으면 그 pool에 있는 참조를 연결해주고, 없으면 새로 넣고 연결해준다고 한다.
그래서 아래와 같은 테스트를 작성하면 확인 할 수 있다.
@Test
void test() {
String expected = "Test String";
String expectedObject = new String("Test String");
String reference = "Test String";
assertEquals(expected, "Test String");
assertEquals(expectedObject, "Test String");
assertThat(expected == "Test String").isTrue();
assertThat(expectedObject.intern() == "Test String").isTrue();
// assertThat(expectedObject == "Test String").isTrue();
assertThat(expected == reference).isTrue();
}
Equals로 비교한 객체 비교는 모두 통과하지만 Object의 == 비교는 리터럴과 스트링 객체간에 서로 다르기 때문에 같지 않다. 대신 expectedObject의 intern method를 호출한 후의 값은 String pool의 참조를 리턴해주기 때문에 동일하게 true로 리턴된다.
또한 리터럴로 동일한 스트링을 선언했을 때(reference String)는 동일하게 String pool에서 같은 참조를 바라보고 있기 때문에 ==, equals가 모두 true로 나온다.
11/14
- JDK Dynamic proxy vs. CGLib Proxy
- 인터페이스가 있으면 dynamic proxy, 아니면 cglib
- JDK Dynamic Proxy
package java.lang.reflect;의 Proxy 클래스 사용
/**
* Returns an instance of a proxy class for the specified interfaces
* that dispatches method invocations to the specified invocation
* handler.
* @param loader the class loader to define the proxy class
* @param interfaces the list of interfaces for the proxy class
* to implement
* @param h the invocation handler to dispatch method invocations to
* @return a proxy instance with the specified invocation handler of a
* proxy class that is defined by the specified class loader
* and that implements the specified interfaces
**/
@CallerSensitive
public static Object newProxyInstance(ClassLoader loader,
Class<?>[] interfaces,
InvocationHandler h)
throws IllegalArgumentException
Proxy 클래스에 메서드 선언부와 문서화 주석 부분을 일부만 보면 위와 같다. 그래서 구현할 프록시 클래스의 인터페이스, InvocationHandler가 필요하다.
- CGLib Proxy
- CGLib proxy는 jdk dynamic proxy 와 다르게 구현할 프록시 클래스의 인터페이스 형태가 필요하지 않고, 해당 클래스 자체로 프록시를 생성 할 수 있다.
- 타겟의 클래스를 상속 받는 프록시 클래스를 생성
public class PersonService {
public String sayHello(String name) {
return "Hello " + name;
}
public Integer lengthOfName(String name) {
return name.length();
}
}
class PersonServiceTest {
@Test
void test() {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(PersonService.class);
enhancer.setCallback((FixedValue) () -> "Hello Tom!");
PersonService proxy = (PersonService) enhancer.create();
String res = proxy.sayHello(null);
assertEquals("Hello Tom!", res);
}
}
sayHello 메서드를 intercept할 프록시 클래스를 만듭니다. Enhancer 클래스는 PersonService를 동적으로 상속받은 프록시를 만들 수 있게 해줍니다.
FixedValue는 단순히 프록시 방식에서 값을 반환하는 콜백 인터페이스입니다. 프록시에서 sayHello() 메서드를 실행 하면 프록시 메서드에 지정된 값이 리턴됩니다.
여기서 문제가 있는데, 프록시가 실행할 메서드와 부모클래스가 호출할 메서드를 직접 결정할 수 없기 때문에 몇 가지 단점이 있습니다.
MethodInterceptor 인터페이스를 사용 하여 프록시에 대한 모든 호출을 인터셉트하고 특정 호출을 수행 할 것인지 슈퍼 클래스에서 메소드를 실행할 것인지 결정할 수 있습니다.
아래 코드에서 if문 분기 처리 부분으로 메서드 호출의 위치를 정할 수 있습니다.
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(PersonService.class);
enhancer.setCallback((MethodInterceptor) (obj, method, args, proxy) -> {
if (method.getDeclaringClass() != Object.class && method.getReturnType() == String.class) {
return "Hello Tom!";
} else {
return proxy.invokeSuper(obj, args);
}
});
PersonService proxy = (PersonService) enhancer.create();
assertEquals("Hello Tom!", proxy.sayHello(null));
int lengthOfName = proxy.lengthOfName("Mary");
assertEquals(4, lengthOfName);
위 예시에서는 메서드 시그니쳐가 Object 클래스 에서 제공되지 않은 경우 모든 Call을 인터셉트합니다. toString () 또는 hashCode () 메소드가 인터셉트 되지 않습니다. 위 코드에서 PersonService의 메서드 중 ReturnType이 String인 메서드만 인터셉트 합니다. 메서드중 lengthOfName()는 인터셉트하지 않습니다.
- BeanCreator
- MixinInterface
참고자료(AOP)
11/12
I/O 처리 관점에서의 용어 설명
- Synchronous
- caller가 callee의 return을 기다리거나 caller가 계속 callee의 작업 완료 여부를 신경씀
- Asynchronous
- callee에 callback 전달, callee 함수의 작업이 완료되면 callback 실행, caller 함수는 작업 완료를 신경쓰지 않음
- Blocking
- 호출된 함수가 자신의 작업을 모두 마칠 때까지 제어권을 넘겨주지 않고, 대기하게 만든다.
- Non-blocking
- 호출된 함수가 바로 리턴해서 호출한 함수에게 제어권을 넘겨주고, 호출한 함수가 다른 일을 할 수 있다.
- WEB에서 polling(Sync와 개념적으로 비슷)
- 일정 주기로 서버에 확인한다. (작업 완료 여부 확인 하는 것처럼, 서버의 변경 내용을 확인한다.)
- push(Async와 개념적으로 비슷)
- 서버에 변경 사항이 발생할 경우 서버에서 클라이언트로 응답 (서버에서 변경이 발생하면 알아서 클라이언트에 응답)
select, epoll, IOCP, kqueue 알아볼 것
11/11
- Binary Search(이진 탐색)
- 정렬된 상태의 배열에서 특정한 값을 찾아내는 탐색법
- 배열의 크기에서 절반씩 쪼개가며 찾는다.
예시로 프로그래머스의 문제 중 징검다리 라는 문제를 풀어보면 아래 처럼 풀 수 있다.
public int solution(int distance, int[] rocks, int n) {
int left = 0;
int right = distance;
Arrays.sort(rocks);
while ((right - left) > 1) {
int mid = (left + right) >> 1;
if (isPossible(rocks, mid, n)) {
left = mid;
} else {
right = mid;
}
}
return right;
}
private boolean isPossible(int[] rocks, int distance, int n) {
int previous = 0;
int count = 0;
for (int rock : rocks) {
if (rock - previous > distance) {
previous = rock;
} else {
count += 1;
}
}
return count <= n;
}
11/10
- 휴식
11/09
- Sticky Session
- 한 WAS에 Session이 종속된다.
- AWS ELB를 사용하면 어떤 사용자가 처음 요청한 서버에만 계속해서 요청을 보낸다.
- 각 인스턴스에 WAS가 떠있고 이 WAS들을 로드밸런싱 구성한 상태여야 한다.
- 하나의 EC2 인스턴스 내에 nginx로 로드밸런싱 -> Docker image 2개 로 구성된 상태라면? (내가 구현했던 방식)
- nginx의 로드밸런싱을 ip_hash 방식으로 구현하면 요청한 IP의 해시값으로 로드밸런싱 하기 때문에, 요청자의 IP가 갑자기 변경되지 않는 한 Sticky하게 한 WAS에만 요청이 간다.
- Load balancing 구성할 때 upstream 쪽에
ip_hash;라는 내용만 추가해주면 된다. - nginx plus에서는 sticky cookie라는 기능을 제공한다고 한다.(Session Persistence)
- 들어온 클라이언트의 요청에 대한 upstream 그룹으로부터 온 첫번째 응답에 session cookie를 담아서 보낸다.
- 그 이후에 session cookie가 담겨있는 클라이언트의 요청은 동일한 upstream server로 보낸다.
sticky cookie srv_id expires=1h domain=.example.com path=/;를 upstream 쪽에 추가해주면 된다.
- Session Clustering
- 여러 WAS간 Session을 하나로 관리한다.
- Load balancing을 위해 여러 WAS로 요청이 분산될 경우에도 login 상태는 유지 되어야 하기 때문에 Session을 하나로 관리할 필요가 있다.
- Tomcat에도 Session Clustering 기능을 제공한다.
- Redis와 같은 세션 서버를 둘 수도 있다.
- Spring boot와 Redis를 활용해서 Session Clustering을 구현할 수 있다.
참고 자료 (Sticky Session)
11/08
- X
11/07
- JPA N+1 문제
- 만약 User라는 Entity가 List<Article>을 갖는다고 생각해보자.
@Entity
public class Article extends BaseEntity implements Comparable<Article> {
@Embedded
private ArticleFeature articleFeature;
@OnDelete(action = OnDeleteAction.CASCADE)
@ManyToOne
private User author;
@Enumerated(EnumType.STRING)
private OpenRange openRange;
...
}
@Entity
public class User extends BaseEntity {
@Embedded
private UserEmail userEmail;
@Embedded
private UserPassword userPassword;
@Embedded
private UserName userName;
@OneToMany(mappedBy = "user", fetch = FetchType.EAGER)
private List<Article> articles = new ArrayList<>();
...
}
User와 Article은 1:N, N:1 양방향 연관관계
jpql로 select u from User u를 날려보면, SQL이 SELECT * FROM USER;로 날아간다. 그러면 User에 Article이 EAGER로 되어있기 때문에, article을 바로 조회한다.
그러면 SELECT * FROM ARTICLES WHERE USER_ID = ?;와 같은 쿼리문이 실행된다. 원했던 쿼리는 하나(SELECT * FROM USER;) 였는데, 이 쿼리의 결과 row수(N) 만큼의 쿼리가 추가로 날아간다.
여기서 만약에 @OneToMany(mappedBy = "user", fetch = FetchType.LAZY)로 바꾼다면 JPQL 자체에서는 N+1 문제가 발생하지 않는다.(User 엔티티 내부의 Articles은 지연로딩 된다, 사용할 때 쿼리가 날아간다.)
그러나 SELECT * FROM USER;로 가져온 UserList를 순회하면서 Article을 사용한다면, 똑같이 쿼리가 N개 더 날아간다.
for (User user : users) {
System.out.println("User = " + user.getArticles().size());
}
이와 같은 식으로 구현한다면 똑같이 N개의 쿼리가 더 날아가게 된다.
해결 방안은
- fetch join을 사용
- jpql
select u from User u join fetch u.articles사용 - SQL은
SELECT U.*, A.* FROM USER U INNER JOIN ARTICLES A ON U.ID = A.USER_ID;처럼 실행된다.
- jpql
- @BatchSize 사용
- List<Article> 위에
@org.hibernate.annotations.BatchSize(size = 5)사용하면 한번에 5개씩 쿼리를 실행한다. - SQL은
SELECT * FROM ARTICLES WHERE USER_ID IN (?, ?, ?, ?, ?)처럼 실행 된다.
- List<Article> 위에
- @Fetch(FetchMode.SUBSELECT)
- Articles를 조회할 때 서브 쿼리를 이용해서 조회한다.
Default는
- @OneToOne, @ManyToOne: EAGER Loading
- @OneToMany, @ManyToOne: LAZY Loading
참고자료
- 자바 ORM 표준 JPA 프로그래밍 15장
11/06
- Nginx의 병렬처리 방식
- Event-driven
- 입출력 이벤트를 감지해 처리가 필요할 때 시그널을 통해 처리한다.
- 싱글 프로세스 기반
- 이벤트를 받는 reactor -> handler -> 각 worker process
- 싱글 프로세스여서 Context Switching 오버헤드가 없다.
- 비동기처리로 인해 적은 메모리로 운영 가능
- 동시 접속 요청이 많아도 프로세스나 쓰레드 생성 비용이 존재하지 않는다.
- 작업을 하다 CPU가 관여하지 않는 작업이 시작되면 기다리지 않고 바로 다른 작업을 수행한다.
- Event-driven
- Apache
- MPM(Multi-Process Module)
- prefork 방식 (다중 프로세스 처리)
- client 요청에 대해 default 개수만큼 apache 자식 프로세스를 생성하여 처리
- 요청이 많을 경우 process를 생성하여 처리
- worker 방식 (멀티 프로세스 - 쓰레드 방식)
- prefork와 동일 하게 default 개수만큼 자식 프로세스를 생성하여 처리
- 요청이 많을 경우 각 프로세스의 쓰레드를 생성해 처리
- prefork 방식 (다중 프로세스 처리)
- 동시 접속 요청이 많을 수록 그 개수만큼 프로세스나 쓰레드 생성을 하기 때문에 리소스가 부족할 수 있다.
- MPM(Multi-Process Module)
11/05
- AOP 관련 용어
- target: 부가 기능을 부여할 대상
- advice: target에 제공할 부가 기능을 담은 클래스
- pointcut: advice가 적용될 target을 지정하는 것을 의미
- joinpoint: advice가 적용될 수 있는 위치. 예를 들어 method의 실행 단계.
Proxy Pattern
- 어떤 객체에 대한 접근을 제어하기 위한 용도로 대리인이나 대변인에 해당하는 객체를 제공하는 패턴
- 가상 프록시
- 생성하는데 많은 비용이 드는 객체를 대신하는 역할
- 실제로 진짜 객체가 필요하게 되기 전까지 객체의 생성을 미루게 해준다.
- Head First Design Pattern에 나온 예시를 들어보면
- Image Icon을 로드하는데 네트워크를 통해 오랜 시간이 걸릴 수 있기 때문에 ImageIcon의 ImageProxy를 만들 수 있다.
- 이 ImageProxy에서는 실제 ImageIcon에서 모든 이미지가 로드 될 때까지 다른 작업을 할 수 있다.(로딩중입니다 라는 메세지를 띄운다거나)
- ImageIcon이 이미지를 로딩이 완료 되면, ImageIcon이 이미지를 화면에 띄우게 된다.
JPA에서 Lazy Loading도 여기서 나오는 가상 프록시와 같은 목적으로 사용한다고 할 수 있다. 실제 객체를 생성하는 데(데이터베이스로부터 조회할 데이터가 많다.)는 많은 비용이 들기 때문에, 실제 안에 내용은 없는 프록시 객체를 생성한 후, 그 객체를 실제로 사용할 때 내용을 데이터베이스로부터 불러오는 것이기 때문이다.
말로만 풀어쓰니 이해가 잘 안될 수 있는데, 실제 책을 보면 이해가 잘 된다.
- 프록시 vs. 데코레이터
- 프록시는 객체에 대한 접근을 제어한다.
- 클라이언트의 입장에서는 자신이 요청을 하는 것이 프록시인지 실제 객체인지 알 수 없다.
- 프록시가 존재할 때 실제 객체는 존재하지 않는 상태일 수 있다.
- 데코레이터는 객체에 행동을 추가해준다.
11/04
- 서버의 다중화에서 데이터 정합성을 얻기 위한 해결방법
- Shared disk
- 실제 공유하는 디스크를 사용한다.
- Shared nothing
- 스토리지 간의 통신을 하여 데이터 정합성을 확보한다.(replication)
- 데이터 송신 측을 Master, 수신측을 Slave라고 한다.
- 동기식 리플리케이션은 오버헤드가 크다.
- 대신 데이터 정합성을 확보하기 좋다.
- 비동기식 리플리케이션은 데이터 손실이 발생할 가능성이 있다.(동기식보다 성능 저하가 적다.)
- Shared disk
- 페일오버 주의점
- Standby -> Active 로 바뀌는 것은 승격이라고 하는데 이 과정에서 일어나는 일련의 동작을 페일오버라고 함.
- Primary가 다운되지 않았음에도 Secondary가 승격해버리는 경우가 생기는데, Split Brain 이라고 부른다.
- 데이터 정합성을 잃게 된다.(?)
- 이를 방지하기 위해 Secondary가 승격할 때 Primary를 강제로 정지시키는 STONITH(Shoot the other node in the head)를 이용한다.
- 부하분산 방법
- Round Robin
- 웹 서버 목록에 있는 리스트 순서대로 액세스를 분산한다.
- Weighted Round Robin
- 설정한 가중치에 따라 액세스를 분산한다.
- Least Connection
- 접속수가 적은 서버에 액세스를 분산한다.
- Weighted Least Connection
- 설정한 가중치와 접속수를 고려해서 액세스를 분산한다. 예를 들어 접속수가 각각 A:B:C:D = 25:50:50:50, 가중치가 A:B:C:D = 1:2:2:2 라면 네 서버가 동일한 가중치로 액세스가 분산된다.
- Round Robin
- 로드밸런서의 헬스체크
- 대부분의 로드밸런서에는 헬스체크 기능이 있다.
- 일정 시간 간격으로 헬스체크 후 응답이 없는 서버를 제외한다.
- 만약 헬스체크 후 응답이 없는 서버를 제외하는 순간에 그 서버에 접속하면 오류가 발생한다.
- 내가 구현했던 nginx 무중단 배포 방법도 이 순간에 문제가 발생할 것이다.(헬스 체크해서 기존 서버(A) 죽이기 전에 기존 서버(A)로 접속한 후 헬스체크 후 A가 죽었을 경우 오류가 발생한다.)
- 대부분의 로드밸런서에는 헬스체크 기능이 있다.
- 백업 시 확인 해야 하는 것
- 백업 타이밍
- 원하는 타이밍에 백업이 되는지 확인해야 한다.(주기라던지..)
- 백업 방법
- 방법이 잘못되면 연동하고 있는 다수의 파일 내용이 백업 처리 중에 변경되는 등의 사태가 발생하여 정합성이 결여된 데이터가 백업 될 수 있다.
- 저장 장소
- 백업의 의미는 원본과 분리되어 있기 때문에 원본에 어떤 문제가 생긴경우 이를 복원할 수 있다는 것이다.
- 리플리케이션이나 RAID 등은 백업이라고 할 수 없다.
- 백업의 의미는 원본과 분리되어 있기 때문에 원본에 어떤 문제가 생긴경우 이를 복원할 수 있다는 것이다.
- 저장 세대의 수
- 몇 세대까지 관리할 것인가.. 버저닝의 문제..
- 백업 타이밍
11/03
- 공부 안했음
11/02
Transaction 격리 수준
Transaction은 크게 아래의 4개로 나뉜다.
- READ UNCOMMITTED
- 어떤 트랜잭션의 변경 내용이 Commit, Rollback 상관 없이 다른 트랜잭션에서 보인다.
- READ COMMITTED
- 어떤 트랜잭션의 변경 내용이 Commit 되어야 다른 트랜잭션에서 보인다.
- Unrepeatable Read가 발생할 수 있다.
- 트랜잭션 시작 후 다른 트랜잭션에서 데이터를 수정, 삭제, 추가 하는 경우 이전에 읽은 내용과 다른 내용이 조회될 수 있다.
- REPEATABLE READ
- 트랜잭션이 시작되기 전에 커밋된 내용에 대해서만 조회할 수 있는 격리수준
- Phantom Read가 발생할 수 있다.
- 트랜잭션 시작 후 다른 트랜잭션에서 데이터가 추가되는 경우, 반복 조회 시 이전 데이터와 조회한 데이터가 달라질 수 있다. (없던 데이터가 생겨날 수 있다.)
- SERIALIZABLE
- 단순 SELECT 문에도 공유 잠금을 한다.
테스트
mysql> select * from department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | 기획부 | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
+------+-----------------+--------+
3 rows in set (0.00 sec)
- READ UNCOMMITTED
# TRANSACTION 1
mysql> SET SESSION transaction isolation level READ UNCOMMITTED;
mysql> commit;
mysql> START TRANSACTION;
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | 기획부 | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
+------+-----------------+--------+
3 rows in set (0.00 sec)
# TRANSACTION 2
mysql> START TRANSACTION;
mysql> UPDATE department SET name = "Test" WHERE name = '기획부';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> INSERT INTO department (dnum, name, mgrssn) VALUES (126, "하하하", 1004);
Query OK, 1 row affected (0.01 sec)
# TRANSACTION 1
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | Test | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
| 126 | 하하하 | 1004 |
+------+-----------------+--------+
TRANSACTION 2에서 commit을 안했는데도 TRANSACTION 1에서 업데이트 된 결과를 볼 수 있음을 알 수 있다. 만약 TRANSACTION 2에서 rollback을 한다면 다시 결과가 처음으로 돌아간다.
# TRANSACTION 2
mysql> rollback;
# TRANSACTION 1
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | 기획부 | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
+------+-----------------+--------+
3 rows in set (0.00 sec)
- READ COMMITTED
# TRANSACTION 1
mysql> SET SESSION transaction isolation level READ COMMITTED;
mysql> commit;
mysql> START TRANSACTION;
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | 기획부 | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
+------+-----------------+--------+
3 rows in set (0.00 sec)
# TRANSACTION 2
mysql> START TRANSACTION;
mysql> UPDATE department SET name = "Test" WHERE name = '기획부';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> INSERT INTO department (dnum, name, mgrssn) VALUES (126, "하하하", 1004);
Query OK, 1 row affected (0.00 sec)
# TRANSACTION 1
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | 기획부 | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
+------+-----------------+--------+
3 rows in set (0.00 sec)
# TRANSACTION 2
mysql> commit;
# TRANSACTION 1
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | Test | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
| 126 | 하하하 | 1004 |
+------+-----------------+--------+
4 rows in set (0.00 sec)
같은 트랜잭션 1에서 같은 SELECT * FROM department 명령에 다른 결과가 나오는 Unrepeatable Read가 발생하는 것을 볼 수 있다.
- REPEATABLE READ
# TRANSACTION 1
mysql> SET SESSION transaction isolation level REPEATABLE READ;
mysql> commit;
mysql> START TRANSACTION;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | Test | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
| 126 | 하하하 | 1004 |
+------+-----------------+--------+
4 rows in set (0.00 sec)
# TRANSACTION 2
mysql> START TRANSACTION;
mysql> INSERT INTO department (dnum, name, mgrssn) VALUES (127, "세번째", 1005);
Query OK, 1 row affected (0.00 sec)
mysql> UPDATE department SET name = "TESTTEST" WHERE name = 'Test';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
# TRANSACTION 1
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | Test | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
| 126 | 하하하 | 1004 |
+------+-----------------+--------+
4 rows in set (0.00 sec)
# Dirty Read는 안 됨
# TRANSACTION 2
# TRANSACTION 1
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | Test | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
| 126 | 하하하 | 1004 |
+------+-----------------+--------+
4 rows in set (0.00 sec)
# TRANSACTION 2
mysql> commit;
# TRANSACTION 1
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | Test | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
| 126 | 하하하 | 1004 |
+------+-----------------+--------+
4 rows in set (0.00 sec)
Phantom Read가 발생하지 않았다. 최신 스냅샷에서 가져오기 때문이다.
This is the default isolation level for InnoDB. Consistent reads within the same transaction read the snapshot established by the first read.
그러나 위의 SELECT 결과에는 없는 ‘TESTTEST’라는 부서를 ‘UpdateTest’ 라는 이름으로 변경하는 쿼리를 날려보면 1 row affected 라는 결과가 나오고, 그 다음 다시 SELECT * 해보면 업데이트가 된 모습을 볼 수 있다.
# TRANSACTION 1
mysql> UPDATE department SET name = 'UpdateTest' WHERE name = 'TESTTEST';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM department;
+------+-----------------+--------+
| dnum | name | mgrssn |
+------+-----------------+--------+
| 123 | UpdateTest | 1001 |
| 124 | 인사부 | 1002 |
| 125 | 정보기획부 | 1003 |
| 126 | 하하하 | 1004 |
+------+-----------------+--------+
4 rows in set (0.00 sec)
참고자료 (Transaction 격리 수준)
TCP와 UDP
- TCP: 신뢰성이 중요한 어떤 Application에 의해 사용될 수 있는 신뢰성 있는 연결 지향 프로토콜
- UDP: 오류 제어가 응용층 프로세스에 의해 제공되는 Application에서 단순성과 효율성으로 사용되는 신뢰성 없는 비연결 전송층 프로토콜
TCP (Transmission Control Protocol)
연결지향, 신뢰성 있는 프로토콜이다.
TCP는 스트림 지향 프로토콜이다. TCP에서는 바이트 스트림으로 데이터를 송, 수신 한다.
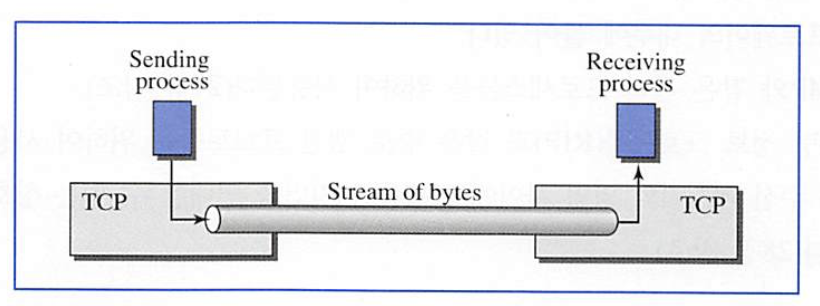
송신, 수신 프로세스가 똑같은 속도로 처리할 수 없기 때문에, TCP는 저장을 위해 버퍼가 필요하다.
TCP 서비스
- 전이중 통신(full-duplex service): 동시에 양 방향으로 전달 될 수 있다.
- 연결 지향 서비스
- 두 사이트 사이에 연결을 설정한다.
- 양 방향으로 데이터를 교환한다.
- 연결을 종료한다.
- 신뢰성 있는 서비스
특징
- Numbering system
- 세그먼트 헤더에는 Sequence number와 Acknowledgement number 영역이 존재한다.
- Sequence Number
- 첫 번째 세그먼트의 Sequence Number는 임의 번호이다.
- 다른 세그먼트의 Sequence Number는 이전 세그먼트의 Sequence Number + 이전 세그먼트의 바이트 수이다.
- Acknowledgement Number
- Ack Number는 상대방으로부터 다음에 받고 싶은 바이트 번호
TCP Segment
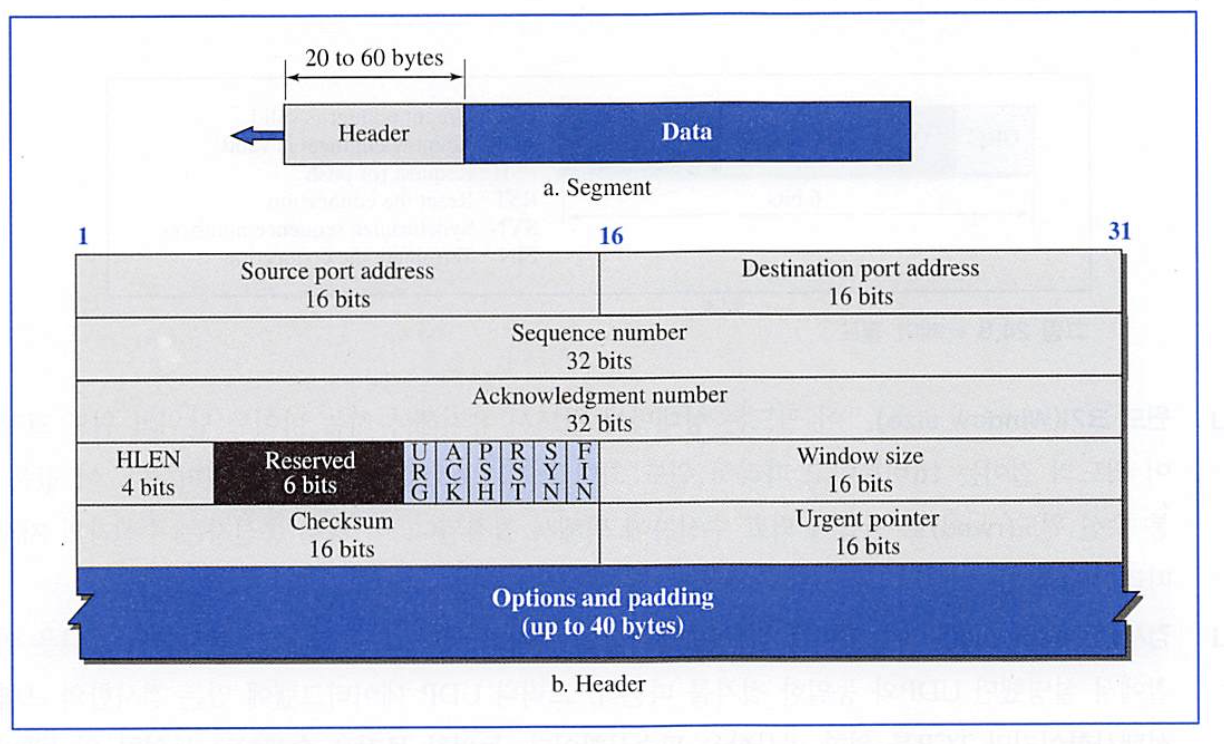
- Source port address
- 세그먼트를 보내는 호스트에 있는 응용 프로그램의 포트 번호
- Destination port address
- 세그먼트를 받는 호스트에 있는 응용 프로그램의 포트 번호
- Sequence Number
- Acknowledgement Number
- 상대로부터 받기를 기대하는 바이트 넘버
- Header Length
- Control
- URG: Urgent pointer is valid
- ACK: Acknowledgement is valid
- PSH: Request for push
- RST: Reset the connection
- SYN: Synchronize sequence numbers
- FIN: Terminate the connection
- Window size
- 상대방이 반드시 유지해야 하는 바이트 단위의 윈도우 크기
- Checksum
- Urgent Pointer
- 세그먼트가 긴급 데이터를 포함하고 있을 때 사용된다.
3-way handshaking
- 클라이언트는 서버에 SYN 세그먼트를 보낸다.
- 서버는 SYN + ACK 세그먼트를 보낸다. (서버 -> 클라이언트 통신을 위한 SYN과 클라이언트 SYN에 대한 ACK)
- 클라이언트가 ACK 세그먼트를 보낸다.(ACK Flag와 Acknowledgement 필드 사용)
SYN flooding attack
Datagram에 있는 source IP를 위조하여 서로 다른 클라이언트로부터 SYN이 들어오는 것처럼 위조해서 SYN을 대량으로 서버에 날릴 수 있다. 서버는 이에 대한 응답으로 SYN + ACK 세그먼트를 날려야하는데, 이 모든 것은 손실된다. 공격자가 많은 서비스 요청을 가진 시스템을 독점한다. denial of service attack으로 알려진 보안 공격 형태에 속한다.
UDP (User Datagram Protocol)
비연결이고, 신뢰성이 없는 전송 프로토콜이다.
일단 User Datagram을 알아보자.
User Datagram이라고 부르는 UDP 패킷은 각각 2바이트인 4개의 필드로 만들어진 고정된 크기의 8바이트 헤더를 가지고 있다. 1,2 번째 필드는 source, destination의 포트 번호이다. 세 번째 필드는 헤더 + 데이터 = 사용자 데이터그램의 전체 길이이다. 마지막 Checksum이다.
예시
CB84000DOO1COO1C - 16진수 형태의 UDP 헤더라고 한다면, Source Port: (CB84 = 52100), Dest Port(000D = 13), User Datagram 전체 길이: (001C = 28바이트), 데이터 길이: 전체 길이 - 헤더 크기(8바이트) = 20바이트
UDP 서비스
- 프로세스 대 프로세스 통신
- Socket Address를 이용
- 비연결 서비스
- 흐름제어 없음
- 오류제어 없음
- 혼잡제어 없음
- UDP는 흐름 및 오류 제어를 하지 않는 간단한 요청-응답 통신을 요구하는 프로세스에 적당하다
- 내부 흐름 및 오류 제어 기법을 가진 프로세스에 적당하다.
- 스트리밍 서비스에 적합하다.
참고자료 (TCP, UDP)
11/01
- Scale up
- 서버의 성능을 증가시킴
- 구축, 설계가 쉽다.
- 확장성 한계
- 정합성 유지가 어려운 경우, DB 서버면 써보자
- Scale out
- 서버의 대수를 증가시켜 처리 능력 향상
- 설계, 구현의 복잡성
- SPOF
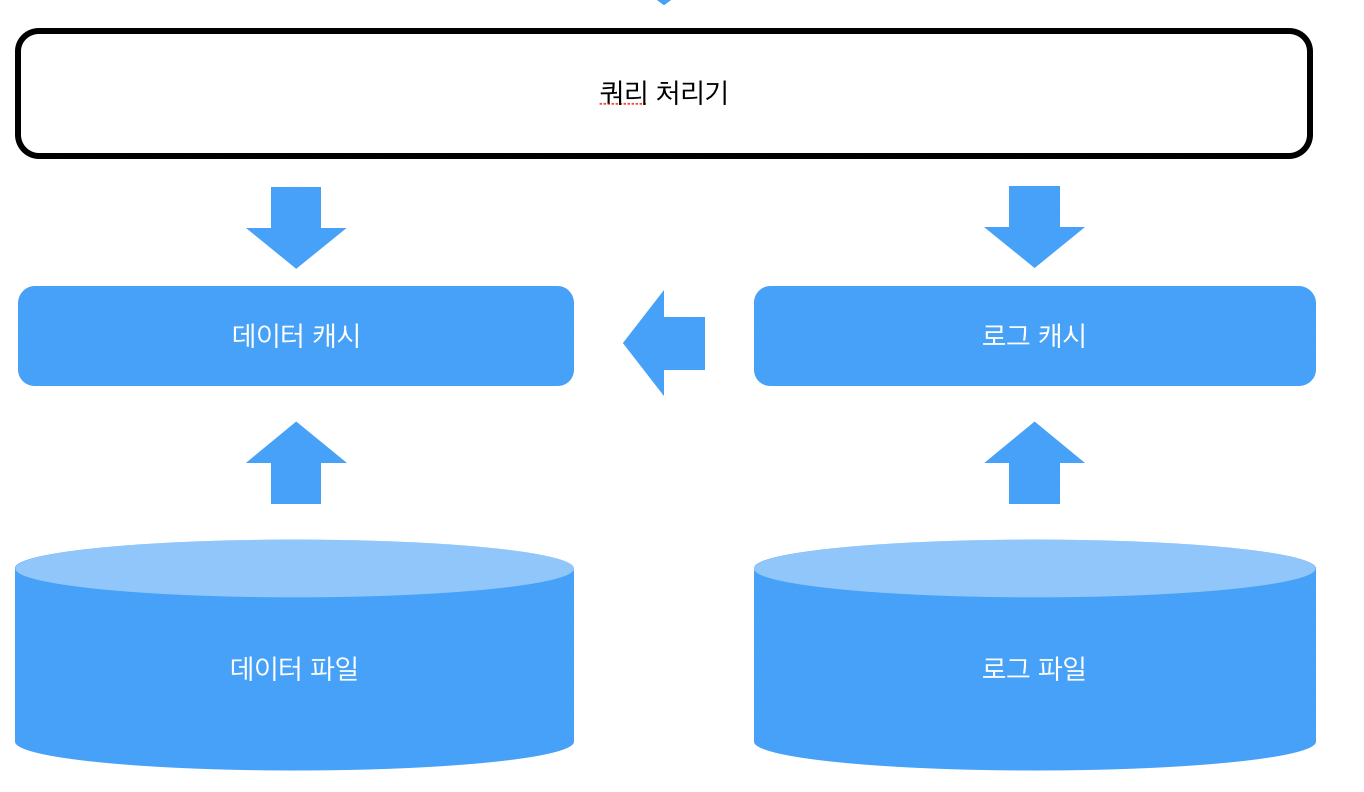
- 트랙잭션 메커니즘
- REDO log(변경 후의 값을 기록한다)
- 커밋한 트랜잭션의 수정은 어떤 경우에도 유지(durability)되어야 한다. 이미 커밋한 트랜잭션의 수정을 재반영하는 복구 작업을 REDO 복구라고 하는데, REDO 복구 역시 UNDO 복구와 마찬가지로 버퍼 관리 정책에 영향을 받는다. 트랜잭션이 종료되는 시점에 해당 트랜잭션이 수정한 페이지들을 디스크에도 쓸 것인가 여부로 두 가지 정책이 구분된다.
- FORCE: 수정했던 모든 페이지를 트랜잭션 커밋 시점에 디스크에 반영하는 정책
- ¬FORCE: 수정했던 페이지를 트랜잭션 커밋 시점에 디스크에 반영하지 않는 정책
- 여기서 주의 깊게 봐야 할 부분은 ¬FORCE 정책이 수정했던 페이지(데이터)를 디스크에 반영하지 않는다는 점이지 커밋 시점에 어떠한 것도 쓰지 않는다는 것은 아니다. 어떤 일들을 했었다고 하는 로그는 기록한다.
- FORCE 정책을 따르면 트랜잭션이 커밋되면 수정되었던 페이지들이 이미 디스크 상의 데이터베이스에 반영되었으므로 REDO 복구가 필요 없게 된다. 반면에 ¬FORCE 정책을 따른다면 커밋한 트랜잭션의 내용이 디스크 상의 데이터베이스 상에 반영되어 있지 않을 수 있기 때문에 반드시 REDO 복구가 필요하게 된다. 사실 FORCE 정책을 따르더라도 데이터베이스 백업으로부터의 복구, 즉 미디어(media) 복구 시에는 REDO 복구가 요구된다. 거의 모든 DBMS가 채택하는 정책은 ¬FORCE 정책이다.
- UnDo log(변경 전의 값을 기록한다)
- 오퍼레이션 수행 중에 수정된 페이지들이 버퍼 관리자의 버퍼 교체 알고리즘에 따라서 디스크에 출력될 수 있다. 버퍼 교체는 전적으로 버퍼의 상태에 따라서 결정되며, 일관성 관점에서 봤을 때는 임의의 방식으로 일어나게 된다. 즉 아직 완료되지 않은 트랜잭션이 수정한 페이지들도 디스크에 출력될 수 있으므로, 만약 해당 트랜잭션이 어떤 이유든 정상적으로 종료될 수 없게 되면 트랜잭션이 변경한 페이지들은 원상 복구되어야 한다. 이러한 복구를 UNDO라고 한다. 만약 버퍼 관리자가 트랜잭션 종료 전에는 어떤 경우에도 수정된 페이지들을 디스크에 쓰지 않는다면, UNDO 오퍼레이션은 메모리 버퍼에 대해서만 이루어지면 되는 식으로 매우 간단해질 수 있다. 이 부분은 매력적이지만 이 정책은 매우 큰 크기의 메모리 버퍼가 필요하다는 문제점을 가지고 있다. 수정된 페이지를 디스크에 쓰는 시점을 기준으로 다음과 같은 두 개의 정책으로 나누어 볼 수 있다.
- STEAL: 수정된 페이지를 언제든지 디스크에 쓸 수 있는 정책
- ¬STEAL: 수정된 페이지들을 최소한 트랜잭션 종료 시점(EOT, End of Transaction)까지는 버퍼에 유지하는 정책
- STEAL 정책은 수정된 페이지가 어떠한 시점에도 디스크에 써질 수 있기 때문에 필연적으로 UNDO 로깅과 복구를 수반하는데, 거의 모든 DBMS가 채택하는 버퍼 관리 정책이다.
- REDO log(변경 후의 값을 기록한다)
정리해보면 DBMS는 버퍼 관리 정책으로 STEAL과 ¬FORCE 정책을 채택하고 있어, 이로 인해서 UNDO 복구와 REDO 복구가 모두 필요하게 된다. UNDO 복구 때에는 이전 이미지로 현재 이미지를 대체하며, REDO 복구 때에는 이후 이미지를 반영하는 방식으로 복구가 이루어진다. UNDO 복구, REDO 복구는 멱등성(idempotent)을 가져야 한다
UNDO Log가 없는 상황이라도 REDO Log를 통해 재 실행 하면서 UNDO Log를 다시 만들 수 있다.
ACID
- Atomicity(원자성): 이체 과정 중에 트랜잭션이 실패하게 되어 예금이 사라지는 경우가 발생해서는 안 되기 때문에 DBMS는 완료되지 않은 트랜잭션의 중간 상태를 데이터베이스에 반영해서는 안 된다. 즉, 트랜잭션의 모든 연산들이 정상적으로 수행 완료되거나 아니면 전혀 어떠한 연산도 수행되지 않은 상태를 보장해야 한다. atomicity는 쉽게 ‘all or nothing’ 특성으로 설명된다.
- Consistency(일관성): 고립된 트랜잭션의 수행이 데이터베이스의 일관성을 보존해야 한다. 즉, 성공적으로 수행된 트랜잭션은 정당한 데이터들만을 데이터베이스에 반영해야 한다. 트랜잭션의 수행을 데이터베이스 상태 간의 전이(transition)로 봤을 때, 트랜잭션 수행 전후의 데이터베이스 상태는 각각 일관성이 보장되는 서로 다른 상태가 된다. 트랜잭션 수행이 보존해야 할 일관성은 기본 키, 외래 키 제약과 같은 명시적인 무결성 제약 조건들뿐만 아니라, 자금 이체 예에서 두 계좌 잔고의 합은 이체 전후가 같아야 한다는 사항과 같은 비명시적인 일관성 조건들도 있다.
- Isolation(독립성): 여러 트랜잭션이 동시에 수행되더라도 각각의 트랜잭션은 다른 트랜잭션의 수행에 영향을 받지 않고 독립적으로 수행되어야 한다. 즉, 한 트랜잭션의 중간 결과가 다른 트랜잭션에게는 숨겨져야 한다는 의미인데, 이러한 isolation 성질이 보장되지 않으면 트랜잭션이 원래 상태로 되돌아갈 수 없게 된다. Isolation 성질을 보장할 수 있는 가장 쉬운 방법은 모든 트랜잭션을 순차적으로 수행하는 것이다. 하지만 병렬적 수행의 장점을 얻기 위해서 DBMS는 병렬적으로 수행하면서도 일렬(serial) 수행과 같은 결과를 보장할 수 있는 방식을 제공하고 있다.
- Durability(지속성): 트랜잭션이 성공적으로 완료되어 커밋되고 나면, 해당 트랜잭션에 의한 모든 변경은 향후에 어떤 소프트웨어나 하드웨어 장애가 발생되더라도 보존되어야 한다.
댓글남기기