Single Point Of Failure
SPOF - Single Point Of Failure
A single point of failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working.[1] SPOFs are undesirable in any system with a goal of high availability or reliability, be it a business practice, software application, or other industrial system.
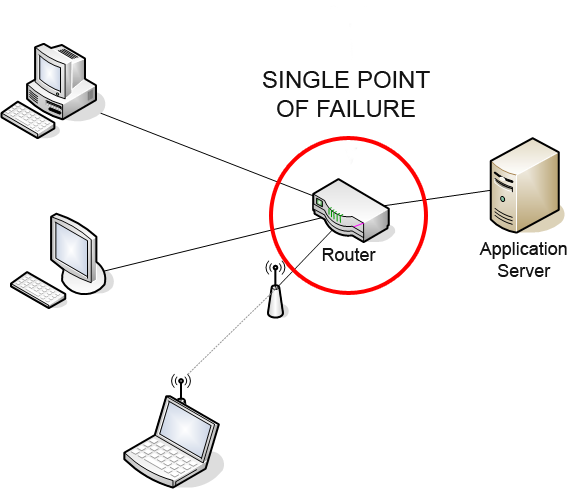
설명하자면, SPOF는 회로나 시스템의 설계, 구현 또는 구성에 결함이 발생하여 하나의 고장 또는 오작동으로 전체 시스템이 작동을 중지하는 잠재적 위험이다.
데이터 센터 또는 기타 IT 환경에서 SPOF는 장애와 관련된 위치와 상호의존성에 따라 워크로드 또는 전체 데이터 센터의 가용성을 훼손할 수 있다.
단일 서버가 단일 애플리케이션을 실행하는 데이터 센터를 예시로 들어보자. 서버 하드웨어는 애플리케이션의 가용성에 단일 장애 지점을 제공한다. 서버에 오류가 발생하면 애플리케이션이 불안정해지거나 완전히 손상될 수 있다. (중요한 데이터가 날아갈 수 있다.)
이런 상황에서 단순하게 애플리케이션을 각각의 물리 서버에서 따로 띄워서 SPOF의 한 부분을 제거할 수 있다. 1, 2번 물리 서버에서 각각 애플리케이션을 띄웠다면, 1번 서버에 장애 발생 시 2번 서버가 애플리케이션에 대한 처리를 진행하고, 1번 서버의 장애를 해결하거나 (1번 서버가 장애가 발생했기 때문에, 2번 서버밖에 남지 않아서)새로 생긴 SPOF를 제거하기 위해 새로운 물리서버를 추가해서 새롭게 애플리케이션을 띄워야 한다.
만약 서버들이 단일 네트워크 스위치(Switch A)를 통해서 네트워크에 연결되는 상황이 있다면, 여기서 단일 네트워크 스위치(Switch A)는 SPOF 지점이다. 여기서 이 Switch A가 고장나거나, 전원과 연결이 끊어지거나 하면 그 스위치와 연결된 모든 서버는 네트워크가 끊어지는 것이다. 그래서 이것도 다중화 해야 하는데, redundant switch와 네트워크 연결은 원래 서버가 고장나면 대체로 사용해야 하는 네트워크 경로를 제공해서 다중화 해야한다.
실제로 우아한테크코스 2단계 프로젝트에서 애플리케이션에 대한 다중화를 하진 않았지만 nginx를 통해 load balancing을 할 기회가 있었는데, nginx를 활용하여 애플리케이션의 다중화를 해서 애플리케이션을 하나 띄우는 것에서 -> 여러개 띄우는 방식으로 SPOF의 한 지점을 없앨 수 있을 것 같다. (하지만 여전히 NGINX 서버가 한대라면 이 지점도 SPOF, AWS EC2도 하나의 instance에서 띄웠기 때문에 이 지점도 SPOF다.)

인프라 설계에 나타나는 단일 장애 지점을 식별하고 수정하는 것은 데이터 센터 설계자의 책임이다. 단, 단일 장애 지점을 극복하는 데 필요한 복원력은 비용(예: 클러스터 내 추가 서버 가격 또는 추가 스위치, 네트워크 인터페이스 및 케이블 연결)을 수반한다는 점을 유념해야 한다.
각 SPOF 지점을 모두 제거하기 위해 다중화 하는 것이 이론 적으로는 맞는 설계지만 비용적인 측면이나 현실적인 문제에 부딪혀 불가능할 수 있다. 각 단일 장애 지점을 다중화 하기 위해 드는 비용과 서비스의 가치를 따져봤을 때 적절한 다중화 수준을 정해야 할 것 같다.
댓글남기기