Sticky Session과 Session Clustering
배경
Sticky Session 과 Session Clustering 이라는 개념은 왜 나왔을까?
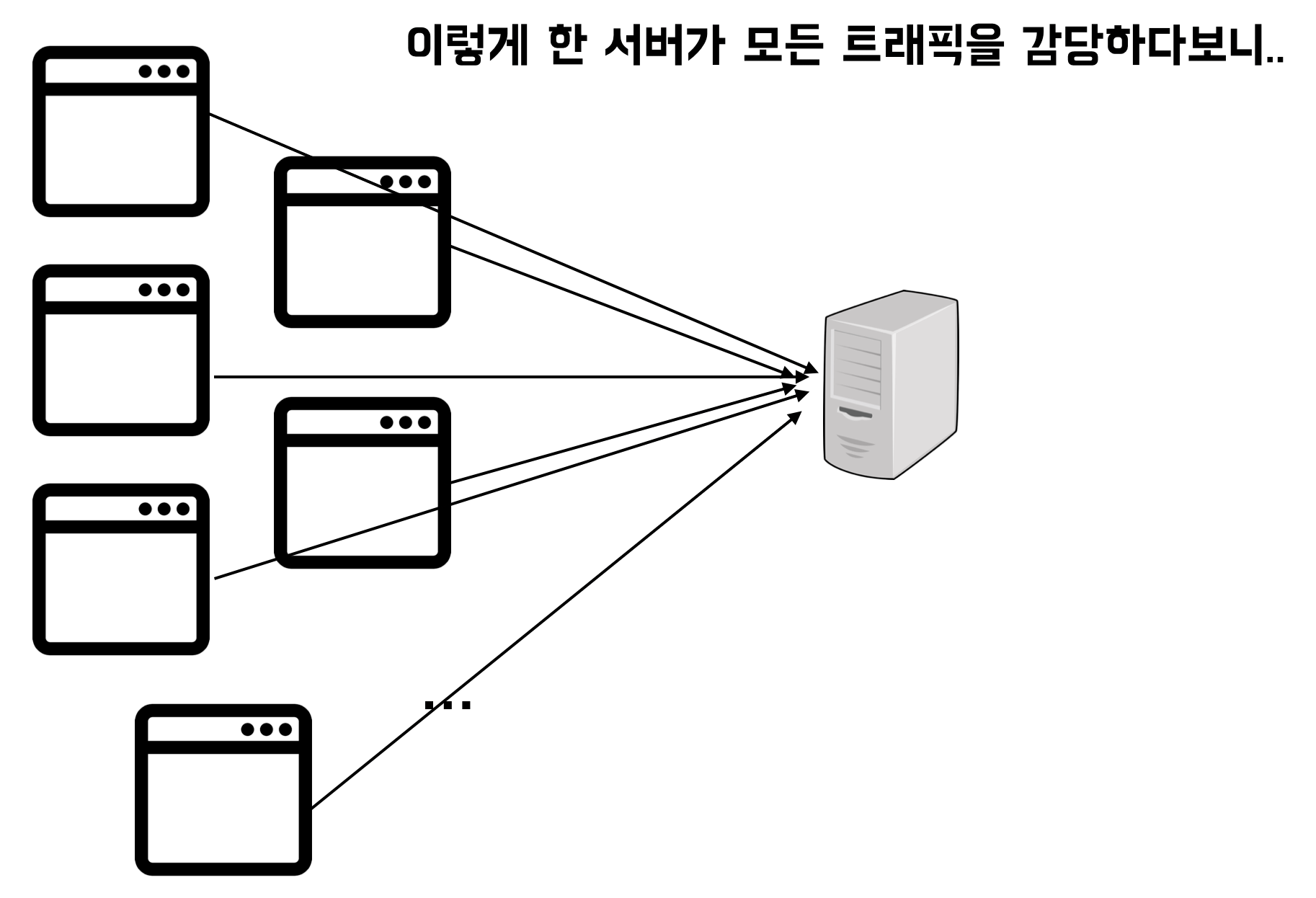
로드 밸런싱
로드 밸런싱이란, 클라이언트로부터 오는 요청을 여러 서버로 분배 해주는 것
다시 말해,
대용량 트래픽을 장애 없이 처리하기 위해 여러 대의 서버에 적절히 트래픽을 분배하는 것
그림으로 살펴보면 아래와 같은 상태로 서버가 구성 되어 있을 수 있다.
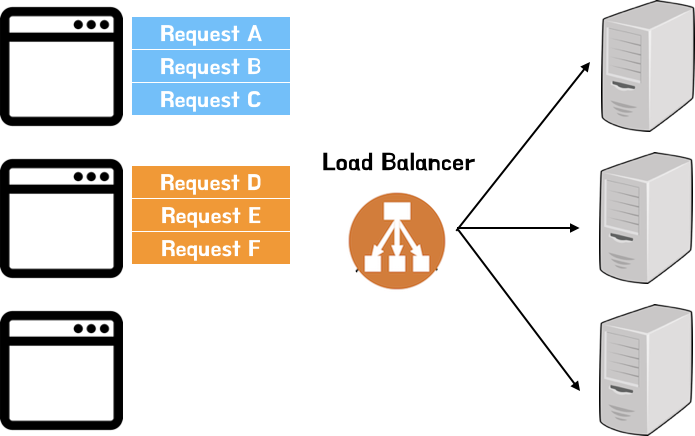
이 상황에서 Request A,B,C,D,E,F는 로드 밸런서를 통해서 동일하게 나누어진다.(단순 Round Robin 방식이라고 한다면)

이렇게 Request를 로드 밸런싱 하는 알고리즘에는 많은 방법이 있다. 로드밸런싱 알고리즘
이렇게 로드밸런싱이 필요한 대규모 트래픽이 발생하는 서비스에서는 세션 관리에 문제가 생길 수 있다.
예를 들어 살펴보면 아래 그림과 같다.
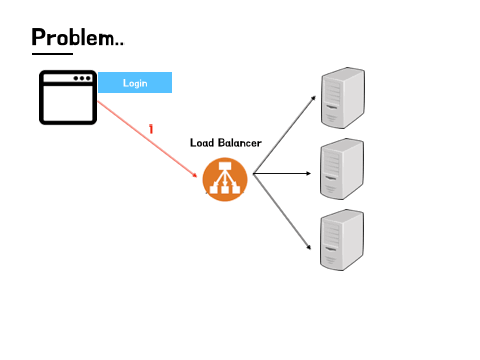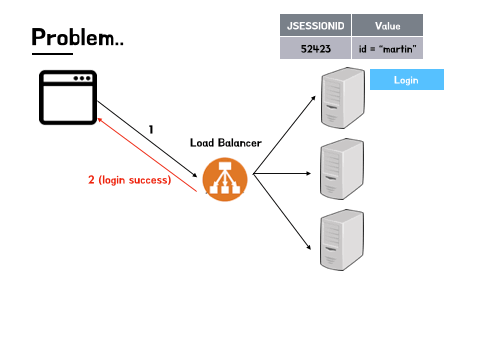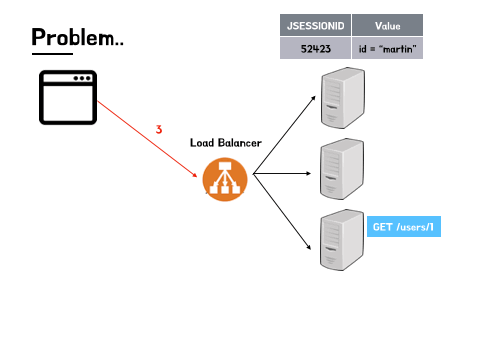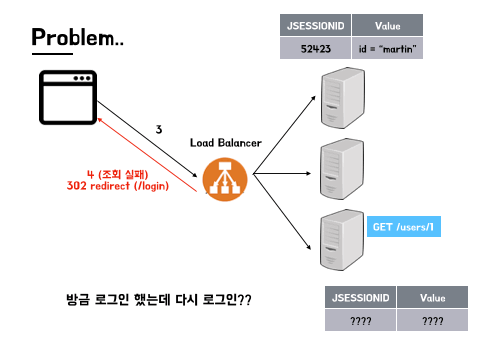
- 먼저 로그인 요청을 A 서버로 보낸다.
- A 서버의 세션에는 martin이라는 값이 저장된다.
- A 서버에서는 로그인 성공이라는 응답을 보낸다.
- 동일한 클라이언트는 다시 로드 밸런서에 유저 정보를 조회하는 요청을 보낸다.(유저 정보 요청에는 로그인 권한이 필요하다고 가정)
- 그러나 이 요청은 로드 밸런서를 통해 C 서버로 전달 된다.
- C 서버의 세션에는 이 사용자가 로그인 한 사용자라는 정보가 없기 때문에, 조회 실패 후 다시 로그인이 필요하기 때문에 로그인 페이지로 리다이렉트 될 것이다.
방금 로그인 했는데.. 바로 또 로그인을 하라고 하는 사태가 발생할 수 있다.
결국 이런 세션 관리의 문제를 해결하기 위한 방법 중 하나는 Sticky Session 을 사용하는 것이다.
Sticky Session
- 첫 request에 대한 응답을 준 서버에 껌딱지처럼 붙어있는 것!
- 특정 세션의 요청을 처음 처리한 서버로만 보내는 것
예를 들어 설명하면 아래 그림과 같다.
- vsh123, oeeen 은 모두 로드 밸런서를 통해 첫 요청을 보낸다.
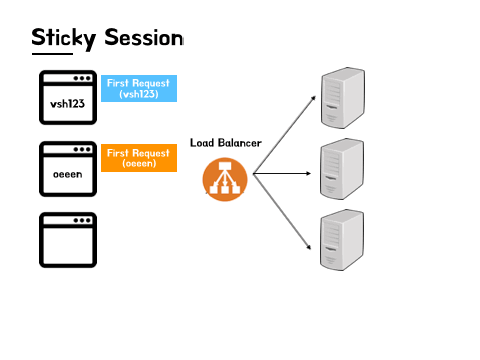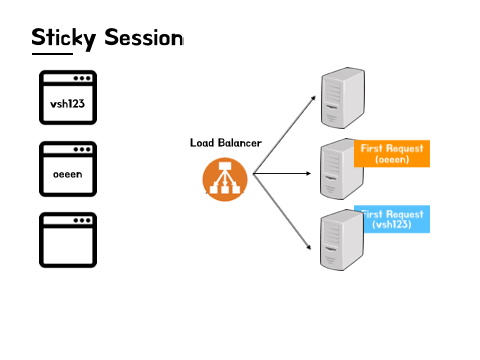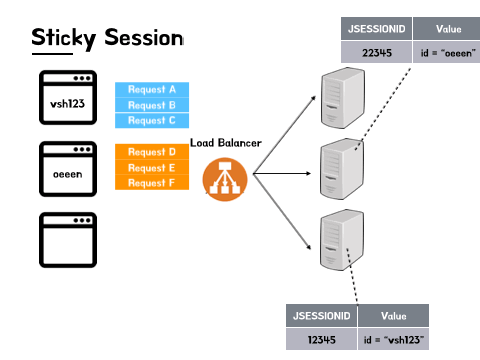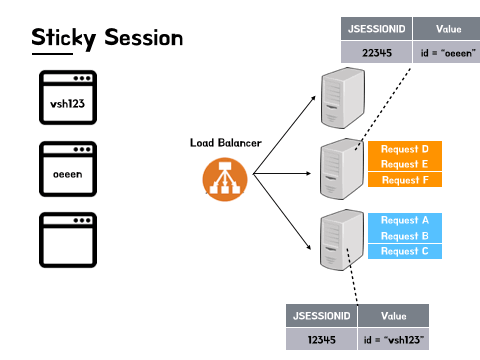
- vsh123의 첫요청은 C 서버로, oeeen의 첫요청은 B 서버로 로드 밸런싱 되었다.
- 그 이후로 들어오는 vsh123의 모든 요청은 C 서버로, oeeen의 모든 요청은 B 서버로 가게 된다.
이렇게 첫 요청 이후의 모든 요청을 특정 서버로 고정하는 방법으로 세션 관리를 한다.
일반적으로 특정 서버로 요청 처리를 고정시키는 방법은 Cookie를 사용하거나 클라이언트의 IP tracking 하는 방식이 있다. 참고로 AWS ELB는 cookie를 사용하여 Http Response에 cookie를 이용해서 해당 클라이언트가 가야하는 EC2 instance의 정보를 저장해두고 그걸 활용하여 특정 EC2로 요청을 고정한다.
예시로 아마존의 ELB(Elastic Load Balancer)와 Sticky session을 읽어보면 좋을 듯 하다. https://aws.amazon.com/ko/blogs/aws/new-elastic-load-balancing-feature-sticky-sessions/
이 Sticky Session은 단순하게 생각해도 단점이 눈에 보인다.
단점
- 로드밸런싱이 잘 동작하지 않을 수 있다
- 특정 서버만 과부하가 올 수 있다.
- 특정 서버 Fail시 해당 서버에 붙어 있는 세션들이 소실될 수 있다.
이러한 단점들을 고려한 세션 관리 기법 중 Session Clustering 방식이 있다.
Session Clustering
- 여러 WAS의 세션을 동일한 세션으로 관리하는 것!

각 WAS들은 세션을 각각 가지고 있지만, 이를 하나로 묶어 하나의 클러스터로 관리하는 것이다.
이 상태에서 하나의 WAS가 fail 발생하면 해당 WAS가 들고 있던 세션은 다른 WAS로 이동되어 그 WAS가 해당 세션을 관리한다.
각 서버마다 세션 클러스터링 방식이 다르고, 지원하는 방식이 다르기 때문에 현재 사용하고 있는 WAS의 session clustering 부분을 보고 확인해야 한다.
하지만 이 방식은 scale out 관점에서 새로운 서버가 하나 뜰 때마다 기존에 존재하던 WAS에 새로운 서버의 IP/Port를 입력해서 클러스터링 해줘야 하는 단점이 있다.
새로운 서버를 띄우면 기존 서버에 수정이 발생하고, 휴먼 에러가 발생할 가능성도 충분히 있다. 그렇기 때문에 Session server를 따로 두고 관리하는 방식도 있다.
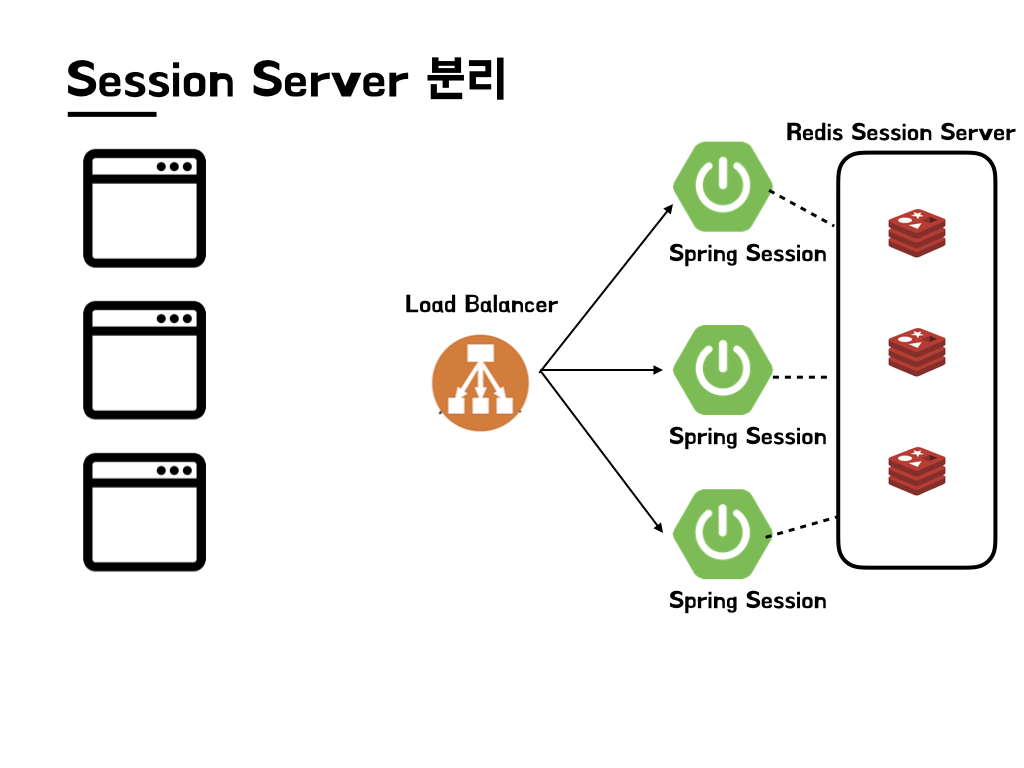
위와 같은 방식은 새로운 서버를 띄우더라도 해당 서버에만 세션 서버의 정보를 적어주고 연결 해주면 되기 때문에 scale out 할 때 기존 서버의 수정이 발생하지 않는다는 장점이 있다.
대신 Redis Session 서버의 중요성이 올라가고, 해당 세션 서버가 죽는 순간 모든 세션이 사라지기 때문에 이 Redis 서버의 다중화도 고려해보아야 할 점이다. (사용해 본 적은 없지만 Redis가 Replication 설정이 쉽다고 한다.)
참고자료
- https://d2.naver.com/helloworld/284659
- https://www.citrix.co.kr/glossary/load-balancing.html
- https://bcho.tistory.com/794
- https://www.imperva.com/learn/availability/sticky-session-persistence-and-cookies/
- https://docs.spring.io/spring-session/docs/current/reference/html5/guides/boot-redis.html
- https://brunch.co.kr/@springboot/114
- http://tomcat.apache.org/tomcat-8.5-doc/cluster-howto.html
댓글남기기