TIL(12월)
틀린 내용이나 본문의 내용과 다른 의견이 있으시면 댓글로 남겨주세요!
12/31
- OAuth
OAuth는 인터넷 사용자들이 비밀번호를 제공하지 않고 다른 웹사이트 상의 자신들의 정보에 대해 웹사이트나 애플리케이션의 접근 권한을 부여할 수 있는 공통적인 수단으로서 사용되는, 접근 위임을 위한 개방형 표준이다. 이 매커니즘은 여러 기업들에 의해 사용되는데, 이를테면 아마존, 구글, 페이스북, 마이크로소프트, 트위터가 있으며 사용자들이 타사 애플리케이션이나 웹사이트의 계정에 관한 정보를 공유할 수 있게 허용한다. (위키백과)
OAuth를 알아보면서 이해가 안되는 이유는 용어가 익숙하지 않아서 라고 생각한다. 그리고 우리가 개발자이기 때문에, 개발할 때는 소비자로서 행동하고 실제 우리가 다른 서비스를 사용할 때는 사용자로서 행동하기 때문에 용어가 헷갈릴 수 있다.
관련된 용어를 살펴보면,
사용자(user): 서비스 제공자와 소비자를 사용하는 계정을 가지고 있는 개인 - github, kakao, naver 계정으로 인증을 하는 사람 소비자(consumer): Open API를 이용하여 개발된 OAuth를 사용하여 서비스 제공자에게 접근하는 웹사이트 또는 애플리케이션 - 사용자에게 인증을 요청하는 애플리케이션 서비스 제공자(service provider): OAuth를 통해 접근을 지원하는 웹 애플리케이션(Open API를 제공하는 서비스) - github, kakao, naver 등.. 소비자 비밀번호(consumer secret) : 서비스 제공자에서 소비자가 자신임을 인증하기 위한 키 - kakao login api 사용할 때 app 생성 하면 발급해주는 키 요청 토큰(request token) : 소비자가 사용자에게 접근권한을 인증받기 위해 필요한 정보가 담겨있으며 후에 접근 토큰으로 변환된다. 접근 토큰(access token) : 인증 후에 사용자가 서비스 제공자가 아닌 소비자를 통해서 보호된 자원에 접근하기 위한 키를 포함한 값.
OAuth인증은 소비자와 서비스 제공자 사이에서 일어나는데 이 인증 과정은 다음과 같다.
- 소비자가 서비스제공자에게 요청토큰을 요청한다.
- 서비스제공자가 소비자에게 요청토큰을 발급해준다.
- 소비자가 사용자를 서비스제공자로 이동시킨다. 여기서 사용자 인증이 수행된다.
- 서비스제공자가 사용자를 소비자로 이동시킨다.
- 소비자가 접근토큰을 요청한다.
- 서비스제공자가 접근토큰을 발급한다.
- 발급된 접근토큰을 이용하여 소비자에서 사용자 정보에 접근한다.
- OAuth 2
OAuth 2 RFC 6749에 나온 Role 부분을 살펴보면 아래와 같다.
- 자원 소유자 (Resource Owner)
- An entity capable of granting access to a protected resource. When the resource owner is a person, it is referred to as an end-user.
- 정보의 소유권을 가진 사용자
- 자원 서버 (Resource Server)
- The server hosting the protected resources, capable of accepting and responding to protected resource requests using access tokens.
- 자원 소유자(Resource Owner)의 정보를 가지고 있는 서버
- 구글, 페이스북, 네이버, 카카오 등
- 인가 서버 (Authorization Server)
- The server issuing access tokens to the client after successfully authenticating the resource owner and obtaining authorization.
- 자원 소유자 (Resource Owner) 을 인증
- Client 에게 Access token 을 발행
- 클라이언트 (Client)
- An application making protected resource requests on behalf of the resource owner and with its authorization. The term “client” does not imply any particular implementation characteristics (e.g., whether the application executes on a server, a desktop, or other devices).
- 사용자 동의하에 Resource Server 에 Resource owner의 정보를 요청 할 수 있다.
인가 서버는 자원 서버와 동일한 서버일 수도 있고, 나누어져 있을 수도 있다. 단일 인가 서버는 여러 자원 서버로부터 받은 access token을 발행 할 것이다.
출처(OAuth)
12/30
- 코드 가독성에 대해
5분 생각해서 변수 명을 고민하거나 적절한 주석을 다는 것으로 다른 개발자가 1시간 고민하는 일을 막을 수 있을지도 모른다.
가독성을 중시해야 할지 말지에 관한 손익분기점은 작업 시간 중 코드를 읽거나 다른 사람에게 코드를 해설하는 시간과 코드를 작성하는 시간 중 어느 쪽이 더 오래 걸리는 지가 하나의 기준이 된다.
프로그래밍 원칙
- Boy Scout 규칙
- 코드를 변경할 때는 더 깔끔하게 만들자.(지저분한 코드를 더 지저분하게 만들지 말라)
- YAGNI(You Aren’t Gonna Need It)
- 필요할 때 만들어라.
- 앞으로 필요해질 것 같다라는 이유로 구현하지 마라.
- 예를 들어 쓰지 않는 유틸 메서드, 구현체가 하나인 인터 페이스 등
- KISS(Keep It Simple Stupid)
- 기능과 사양을 단순화한다, 또는 구현 기법을 단순화한다.
- 목적과 수단이 뒤바뀌지 않도록 유의하자
- 억지로 디자인패턴을 적용하지 마라
- Single Responsibility Pricinple
- SOLID의 S
- 어떤 클래스가 변경되는 이유는 딱 한 가지여야 한다.
- 클래스의 책임과 관심의 범위는 하나로 좁혀야한다.
참고자료(코드 가독성)
12/23
- Paging
페이징이라는 것은 일단 physical memory를 frame이라고 부르는 고정 크기의 블럭으로 쪼개고, logical memory를 page라고 부르는 동일 사이즈의 블럭으로 쪼개는 것이다.
페이징이 수행될 때, 그 페이지는 사용가능한 메모리 프레임에 적재된다. Backing Store(비휘발성 저장장치, SSD 같은)는 메모리 프레임이나 여러 프레임의 클러스터와 같은 크기의 고정 크기의 블럭으로 나누어진다.
페이징을 지원하는 하드웨어에서 모든 주소는 page number와 page offset으로 구성되어 생성된다. page number는 page table의 index로 사용된다. 이 page number는 실제 physical memory의 각 페이지의 base address가 된다. 이 page number와 page offset의 조합으로 실제 physical memory 주소를 정의할 수 있다.
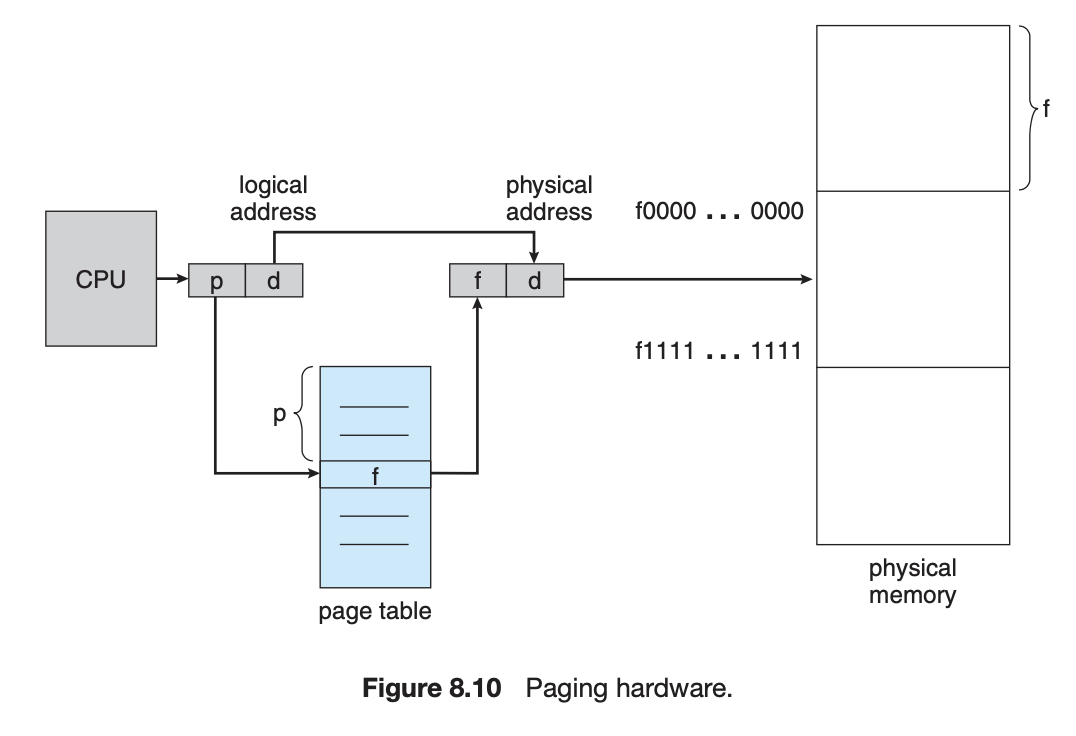
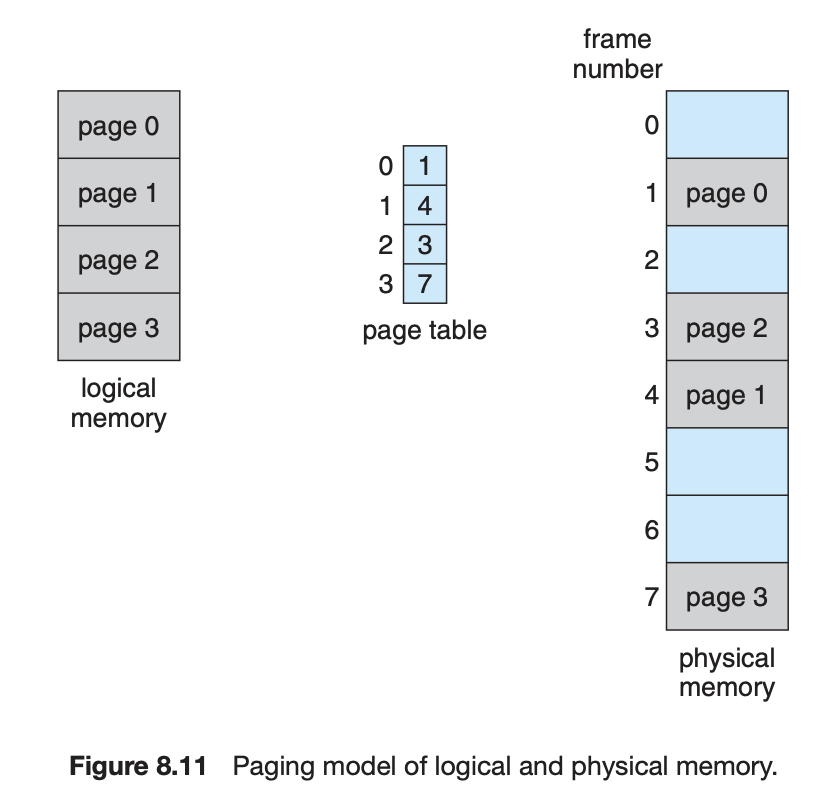
페이지 크기(프레임 크기처럼)는 하드웨어에 의해 정의된다. 페이지의 크기는 컴퓨터 구조에 따라 페이지당 512바이트에서 1GB로 달라지는 2의 승수이다. 2의 승수를 페이지 크기로 선택하면 logical address를 page number와 page offset으로 변환하는 것이 쉽다. logical address 공간의 크기가 2^m이고 페이지 크기가 2^n바이트인 경우 logical address의 상위 m - n 비트 = page number, 하위 n 비트 = page offset으로 볼 수 있다.
예를 들어, 아래 그림처럼 m = 4, n = 2 이고, 페이지 사이즈는 4byte physical memory는 32byte(8page) 라고 해보자.
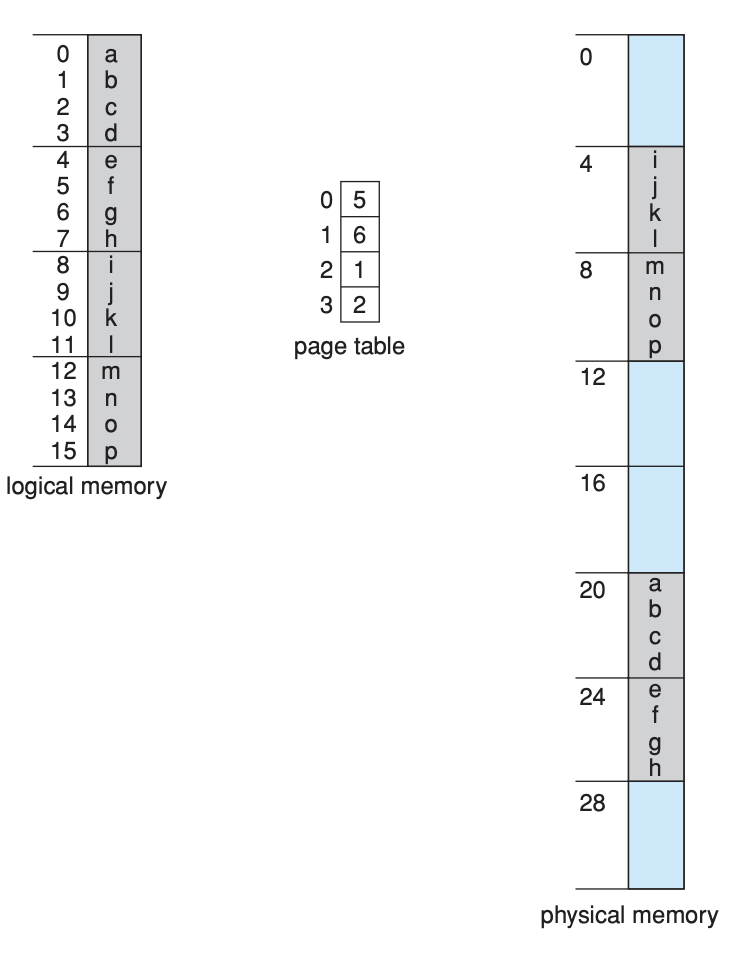
여기서 logical address 0은 page table 안에 frame 5, offset은 0(page 내에서 offset)이다. 따라서 이걸 physical memory에서 찾아보면 5(frame#) * 4(page size) + 0(offset) = 20이 된다. 위에서 말한 예제를 설명하기 위해 다른 예시를 들어보면 logical address 13은 bit로 표현하면 1101 인데, 상위 2 bit는 11(3), 하위 2bit는 01(1) 이다. 그래서 page number = 3, page offset = 1이다. 이를 페이지 테이블에서 찾아보면, frame 2, offset = 1이다. 이를 이용해서 physical memory에서 찾아보면 2 * 4 + 1 = 9이다. physical memory 상의 address 9를 살펴보면 logical memory 상의 n과 동일한 값이 들어있는 것을 볼 수 있다.
이런 페이징 기법을 사용하면 fragmentation이 프로세스 당 최대 1/2 페이지 사이즈 만큼만 발생할 수 있다. 그래서 이상적으로는 page size가 작을수록 좋을 것 같다. 하지만 page table에 포함되는 오버헤드가 있고, 이 때문에 페이지 크기가 적절하게 조절된다.
참고자료 (paging)
- Operating System Concept 9th edition
12/22
Spring에서 DI, IoC Container
의존 객체 주입으로 변화에 유연하게 대응할 수 있게 한다. 한 객체가 다른 객체를 의존하고 있을 때 결합도를 낮출 수 있는 가장 좋은 방법이다.
일반적으로 어플리케이션을 작성하면, 이 어플리케이션의 흐름을 제어하는 것은 어플리케이션 코드이다. 그러나 Spring 기반의 개발에서는 프레임워크가 흐름을 제어하는 주체가 된다.
스프링에서 빈들의 생성 부터 생명주기 까지 책임지고 관리한다. 그렇게 함으로써 개발자는 도메인의 핵심 비즈니스 로직에 더 집중할 수 있게 된다.
스프링에서는 클래스간 의존 관계를 빈 설정 정보를 바탕으로 컨테이너가 자동적으로 연결해준다. Container로부터 주입받아, 실행 시에 동적으로 의존관계가 생성된다.(컨테이너가 흐름을 제어한다)
참고자료 (IoC Container, DI)
@Controller, @Service, @Repository, @Configuration
각 annotation의 주석을 살펴보면 아래와 같다.
/**
* Indicates that an annotated class is a "Service", originally defined by Domain-Driven
* Design (Evans, 2003) as "an operation offered as an interface that stands alone in the
* model, with no encapsulated state."
*
* <p>May also indicate that a class is a "Business Service Facade" (in the Core J2EE
* patterns sense), or something similar. This annotation is a general-purpose stereotype
* and individual teams may narrow their semantics and use as appropriate.
*
* <p>This annotation serves as a specialization of {@link Component @Component},
* allowing for implementation classes to be autodetected through classpath scanning.
*
* @author Juergen Hoeller
* @since 2.5
* @see Component
* @see Repository
*/
DDD에서 말하는 각 레이어 별로 명시할 때 사용한다.
- 클래스가 어느 레이어에 배치될 지 고려해서 결정한다.
@Controller-> presentation layer@Service-> application layer@Repository-> Infrastructure 와 가까운 domain layer (?)@Configuration-> 각 설정에 따른 layer
12/17
StringBuilder, StringBuffer
StringBuffer는 Thread-safe 하다.
StringBuilder, StringBuffer는 String과 비슷하지만 수정가능하다.
String은 String a = "abcd"; String b = a + "efg" 와 같이 선언하면 객체 주소가 바뀐다.
12/16
Wrapper Class vs. Primitive Type
객체를 쓰는 것은 원시 타입을 사용하는 것보다 메모리나 박싱 측면에서 오버헤드가 있다.
오브젝트는 null로 초기화가 가능하고, 메서드나 생성자에 null을 넘길 수도 있다.(원시타입은 안된다.)
Wrapper class는 null 을 반환할 필요가 있을 때나, 객체로 필요할 경우에 사용한다.(generic)
JPA에서 객체를 생성할 때 일단 DB에 들어가기 전에는 id값이 없다. 그래서 null이 필요할 수 있다.
12/11
WebSocket
원격 호스트와 양방향 통신 프로토콜이다. WebSocket은 polling 방식 때문에 생기는 불필요한 네트워크 트래픽과 지연시간을 줄여준다. 단일 커넥션으로 upstream, downstream을 지원한다.
WebSocket 프로토콜은 이미 있던 웹 인프라에서 잘 동작하는 것을 기반으로 디자인 되었다. 그래서 프로토콜의 스펙은 HTTP connection의 life로부터 시작된다. HTTP로부터 WebSocket으로의 변환은 WebSocket handshake로 할 수 있다.
HTTP 에서 WebSocket으로 프로토콜 전환
HTTP의 Header에 Upgrade 속성을 추가하여 서버에 보냄, 이 WebSocket 프로토콜을 이해하는 서버라면, Upgrade 속성으로 프로토콜 전환을 하고 ws프로토콜을 사용하게 된다.
GET ws://echo.websocket.org/?encoding=text HTTP/1.1
Origin: http://websocket.org
Cookie: __utma=99as
Connection: Upgrade
Host: echo.websocket.org
Sec-WebSocket-Key: uRovscZjNol/umbTt5uKmw==
Upgrade: websocket
Sec-WebSocket-Version: 13
HTTP/1.1 101 WebSocket Protocol Handshake
Date: Fri, 10 Feb 2012 17:38:18 GMT
Connection: Upgrade
Server: Kaazing Gateway
Upgrade: WebSocket
Access-Control-Allow-Origin: http://websocket.org
Access-Control-Allow-Credentials: true
Sec-WebSocket-Accept: rLHCkw/SKsO9GAH/ZSFhBATDKrU=
Access-Control-Allow-Headers: content-type
참고자료(WebSocket)
12/08
What is a Reverse Proxy vs. Load Balancer
각각의 뜻은 간단하다.
리버스 프록시는 클라이언트로부터 요청을 받고 서버로 그 요청을 포워딩 해주고, 서버로부터 받은 응답을 클라이언트로 되돌려 준다.
로드 밸런서는 들어오는 클라이언트의 요청을 여러 서버들로 분배 해준다. 서버로부터 온 응답은 적합한 클라이언트에 되돌려 준다. 말로는 엄청 간단해보인다. 리버스 프록시와 로드 밸런서 모두 클라이언트와 서버 사이에 위치해 있다(요청을 받아서 응답을 전달해준다는 측면에서).
Load Balancing
로드 밸런서는 일반적으로 한 서버로 오는 요청이 효율적으로 처리하기에는 너무 커서 사이트가 여러 서버를 필요로 할 때 사용한다. 여러 서버를 배포하는 것은 SPOF를 없애주고 웹사이트를 좀 더 신뢰성 있게 해준다. 일반적으로 서버는 모두 동일한 컨텐츠를 호스트하고, 로드 밸런서의 일은 각 서버의 용량을 최대한 활용하고, 서버에 과부하를 방지하며, 클라이언트에 가능한 가장 빠른 응답을 하는 방식으로 워크로드를 분배하는 것이다.
로드 밸런서는 클라이언트가 보는 에러 응답의 수를 줄임으로써 사용자 경험을 향상 시킬 수 있다. 서버가 다운되는 경우를 감지하고, 요청을 그룹 내의 다른 서버로 분산시킴으로써 이것을 실현시킨다. 가장 간단한 구현에서, 로드 밸런서는 규칙적인 요청으로부터 에러 응답을 감지해 서버의 상태를 감지한다. 애플리케이션의 health check는 좀 더 유연하고 정교한 방법(로드 밸런서가 헬스 체크 요청을 보내고, 그 헬스 체크를 고려한 타입의 요청)이다.
어떤 로드 밸런서의 또 다른 유용한 기능은 특정한 클라이언트로부터 오는 모든 요청은 같은 서버로 보내는 세션 유지이다. HTTP는 이론 상 무상태 프로토콜이지만, 많은 애플리케이션은 그들의 핵심 기능을 제공하기 위해서 상태 정보를 저장해야 한다. 그런 애플리케이션들은 이런 로드 밸런싱 환경에서 로드 밸런서가 처음 요청에 대한 응답을 한 서버로만 하나의 유저 세션을 고정하지 않고, 한 유저 세션의 요청을 여러 다른 서버로 나누어 버리는 경우에 기능 수행이 제대로 안될 수 있다.
Reverse Proxy
여러 서버를 필요로 한다면 로드 밸런서를 사용하는 것이 옳지만, 단일 웹서버나 WAS를 사용하더라도 리버스 프록시를 사용하는 것이 좋다. 간단하게 생각해서 리버스 프록시는 웹사이트의 public face라고 생각하면 된다. 그 주소는 웹사이트에 광고된 것이고, 그것은 웹사이트에서 호스팅되는 콘텐츠에 대한 요청을 받아들이기 위해 네트워크의 edge에 위치한다.(?) 장점은 두 가지가 있다.
- 보안 향상 - 내부 네트워크 외부에서 백엔드 서버에 대한 정보가 없기 때문에, 악의를 가진 클라이언트가 취약점을 이용하기 위해 직접 서버에 접근할 수 없게 한다. 많은 리버스 프록시 서버는 DDoS 공격으로부터 백엔드 서버를 보호하는 기능을 포함하고 있다. (특정 아이피로 들어오는 트래픽을 차단하거나, 각 클라이언트로부터 오는 connection 수를 제한 한다거나..)
- 확장성 및 유연성 향상 - 클라이언트는 리버스 프록시의 아이피만을 알기 때문에, 백엔드 서버 인프라 구조의 설정을 자유롭게 바꿀 수 있다. 이는 트래픽양에 따라 서버의 수를 늘리거나 줄이는 로드 밸런싱 된 환경에서 특히 유용하다.
- 또 다른 이유는 웹 가속화를 위해 리버스 프록시를 사용한다. - 응답을 만들고, 클라이언트로 응답을 되돌려주는 시간을 줄여준다. 그 방법은 아래와 같다.
- 압축 – 클라이언트로 반환 하기전에 서버의 응답을 압축(예를 들면, gzip)하면 필요한 대역폭을 줄일 수 있어서 네트워크를 통한 전송속도를 높여준다.
- SSL termination – 클라이언트와 서버간의 트래픽을 암호화 하면, 인터넷 같은 퍼블릭 네트워크를 통해서 통신할 때 정보를 보호할 수 있다. 그러나 암호화, 복호화는 계산적으로 비쌀 수 있다. 요청을 복호화하고, 서버의 응답을 암호화함으로써 리버스 프록시는 백엔드 서버의 리소스를 본인의 역할(컨텐츠 제공)에 충실할 수 있도록 해준다.
- 캐싱 - 백엔드 서버의 응답을 클라이언트로 반환하기 전에 리버스 프록시는 그 응답을 로컬에 저장한다. 클라이언트가 똑같은 요청을 만들어서 보낸다면, 리버스 프록시는 요청을 백엔드 서버로 포워딩 하지 않고, 리버스 프록시의 캐시로부터 응답을 만들어서 보낼 수 있다. 이를 통해 응답 속도를 올리고, 백엔드 서버의 부하를 줄여준다.
댓글남기기