1일 1질문, TIL(10월)
틀린 내용이나 본문의 내용과 다른 의견이 있으시면 댓글로 남겨주세요!
의식적인 노력을 통해 하루에 질문을 한개씩
하루에 질문을 한개씩 할 수 있도록 강제하기 위해 쓰는 글입니다. 주말에는 TIL(Today I Learned)로 대체합니다.
10/31 TIL
- DB property 같은 보안에 민감한 데이터들을 어떻게 관리할까?
- Git Submodule을 활용할 수도 있다.
- Private repository 활용하면 된다. 전에는 1개만 무료였는데, 지금은 무제한이다.
- Load Balancer의 이중화
- 이중화된 로드밸런서는 서로 Health Check를 한다.
- Main 로드 밸런서가 죽으면 나머지 하나의 로드 밸런서로 운영된다.
- Load Balancing
- 부하 분산을 위해서 virtual IP를 통해 여러 서버에 접속하도록 분배하는 기능. 주요 기술은 아래.
- NAT(Network Address Translation): 사설 IP -> 공인 IP
- DSR(Dynamic Source Routing protocol): 서버에서 클라이언트로 되돌아가는 경우, 목적지 주소를 스위치의 IP말고 클라이언트의 IP로 전달해서 스위치를 거치지 않는다.
- Tunneling: 데이터를 캡슐화해서 연결된 상호 간에만 캡슐화된 패킷을 구별해 캡슐화를 해제할 수 있다.
- 부하 분산을 위해서 virtual IP를 통해 여러 서버에 접속하도록 분배하는 기능. 주요 기술은 아래.
- L4 스위치는 IP,포트,세션을 기반으로한 로드밸런싱이다.
- 동일한 역할을 수행하는 서버 그룹을 VIP를 통해 관리하며, 서버로 향하는 트래픽을 일단 VIP를 가진 L4 스위치로 수신한 뒤 분배 정책에 따라 적절한 서버에 분배해 주는 것을 말한다.
- 클라이언트는 VIP로 요청하고, L4 스위치가 요청을 받아서 적절한 서버에 로드밸런싱 해준다.
10/30 TIL
- Blue Green 배포, A/B Testing, Canary Release
- Blue Green 배포는 이번 미니프로젝트에서 내가 진행한 것.
- 간단하게 새롭게 그린 컨테이너가 떠있는 상태에서 새로운 배포버전이 블루 컨테이너로 뜨게 되고, 아무런 이슈가 없다면 블루 컨테이너를 사용한다.
- 블루 컨테이너 배포 후 문제가 생긴다면 다시 그린 컨테이너로 롤백한다.
- A/B Testing은 어플리케이션의 버전이 바뀌면서 새롭게 UI/UX가 변경되거나 Application의 기능을 테스트하기 위해 사용한다.
- Canary Release는 로드밸런서에 물린 여러 애플리케이션에 임시로 새로운 버전의 Canary를 배포해보고 문제가 생긴다면 Canary를 철수하고 롤백한다.
- Blue Green 배포는 이번 미니프로젝트에서 내가 진행한 것.
10/30 자기소개서
- 기본
- 프로젝트 언급 순서는 역순 (가장 최근이 제일 위로)
- pdf로 만들어서 내라 (pdf는 브라우저에서 바로 열린다.) (hwp, docx 이런 것좀 하지말자)
- 압축(zip파일) 하지 마세요. (이력서 제출하라는 곳에서 하라고 한거 아니면..)
- 본인 프로필(이름, github 주소, 블로그 주소)
- 본인 소개
- 기술 스택
- 그냥 튜토리얼 수준으로 해본 기술 스택은 적지말자.
- 한 번 해본 건 웬만하면 적지말자.
- 과거 프로젝트에서 다른 기술 스택 사용한 것 - 자세하게 답변 할 자신 없으면 쓰지말자
- 오픈소스, 프로젝트, 경력
- 교육, 발표, 집필
- 회사는 좋은 사람을 놓치는 것보다 안좋은 사람을 뽑는걸 더 두려워 한다.
- 경력이라면 프로젝트 기술에서 최대한 숫자로 표현 - RPM/TPS/PV/MAU 등 구체적 숫자.
- 신입이 숫자가 어딨냐? 라면..
- 개발자의 자세를 강조
- 배우려고 하는 자세
- 본인의 부족한 점을 부끄러워하고 걱정할 줄 알아야한다.
- 좋은 질문을 하는 자세
- 질문에 대한 답이 납득이 되지 않으면 검증하고 다시 질문하는 사람.
- 물어보고 A라는 답변이 왔을 때 아 A가 맞구나~ 무작정 믿는 사람이 아니라, 직접 본인이 확인해보고 검증해보는 것이 좋다.
- 배우려고 하는 자세
- 개발자의 자세를 강조
- 피할 단어
- 열정 / 노력 / 도전 정신
- 이런 거 없다고 하는 사람이 있을까..?
- 열정 / 노력 / 도전 정신
- 지원하는 분야랑 다른 기술 스택을 사용한 프로젝트를 언급할 땐 프로젝트에서 배운 태도를 말할 때 쓰자. 기술의 의미는 거의 없다.
- 지원서에 특정 기술을 사용하기 때문에 이 회사에 지원했다. 라고 쓰지말자(그 회사에서 만약 다른 기술로 갈아타야 한다면 퇴사하실 건가요?)
- github이나 블로그로 본인의 코드를 보여라
- 책을 읽는 것은 중요하다. 책에서는 정제된 기술의 전반적인 지식을 얻을 수 있다.(내 생각에 공식문서를 읽는 것도 좋은 것 같다.)
- 스택 오버플로우에서는 순간적이고 단편적인 문제의 해결법만 알 수 있다. 살짝 응용되어 바뀌면 다시 찾아봐야 할 것이다.
- 새로운 기술에 대한 소개와 같은 책도 좋지만, 프로그래밍 전반에 깔려있는 개념이나 전체적인 구조에 대한 학습을 할 수 있는 책이 좋다. (TDD, 클린코드, 오브젝트..)
10/29
추측성 글입니다 (정확한 내용이 아닙니다)
- DB property 같은 보안에 민감한 데이터들을 어떻게 관리할까?
- Java 기준으로 properties를 gitignore 해놓고, 따로 배포 서버에 옮기는 방법도 가능하다.
- 하지만 자동화가 불가능하다.
- Travis CI 에서는 환경변수로 관리할 수 있다.
- Jenkins에서는 어떤 방법이 있을까?
- Public github을 사용하지 않고 내부에 Git server를 구축하여 사용할 수도 있다.
- Java 기준으로 properties를 gitignore 해놓고, 따로 배포 서버에 옮기는 방법도 가능하다.
- Test 작성할 때 DB에 연관성 없는 테스트들만 작성할까?
- 아니다.
- 우리가 보통 구현할 때 DB에 연관있는 테스트가 있으면, 테스트 전용 데이터 베이스(보통 In-memory DB)를 사용했었다.
- 테스트 전용 DB에서 모든 테스트가 통과한다면, Database 관련 로직 제외하고 모든 로직은 테스팅 됬다고 생각할 수 있을 것 같다.
- 개발 서버에서는 실제 배포 서버에서 사용하는 DB의 스키마를 그대로 사용해도 될 것 같다.
- 만약 DB에 영향을 미치는 테스트가 있다면 실제 운영서버에서는 활용할 수 없을 것 같다.
- 그러면 개발 및 운영에 사용할 서버를 어떻게 배치할까
- 로컬 개발 환경
- 개발자 각각의 PC 환경, 우리의 맥북이다.
- 서버 개발 환경
- 실제 서버 환경에서 테스트 할 수 있다.
- 로컬 PC에선 되지만 서버에선 안되는 문제를 발견할 수 있다.
- 기능구현이 가능한 정도로만 구성한다. 최소한의 Set으로 구성한다.
- Integration
- 여러개의 컴포넌트를 동시 개발하는 프로젝트에서 컴포넌트를 통합 및 테스트 하는 환경으로 사용한다.
- QA
- 테스트 환경은 QA 엔지니어에 의해서 사용되는 환경으로, short release 주기에 따라서, 개발환경에서 QA 환경으로 배포 되고, 여기서 기능 및 비기능 (Load Test)등을 QA 엔지니어가 수행한다.
- Staging
- 운영 환경과 거의 동일한 환경을 만들어 놓고 운영환경으로 이전하기 전에 여러 가지 비 기능적인 부분을 검증하는 환경이다.
- Production
- 실제 서비스를 위한 운영 환경
- 로컬 개발 환경
10/27
- DI (Dependency Injection)
- 의존 객체 주입으로 변화에 유연하게 대응할 수 있게 만든다.
- A객체가 B객체를 의존하고 있을 때 결합도를 낮출 수 있는 가장 좋은 방법이다.
- 과거에 전략패턴을 사용해서 전략을 주입해주는 것도 또한 DI라고 할 수 있을 것 같다.
- 예시를 들어보면, SpellChecker
public class SpellChecker {
private Lexicon dictionary = new EnglishKoean();
...
}
이 상태에서 다른 구현체(중국어 사전, 일본어 사전)이 필요해 진다면? dictionary2, dictionary3 같은 필드들이 추가될 것이다. 또한 if문으로 dictionary를 선택하는 로직까지 추가될 것이다.
이런 것을 방지하기 위해 dictionary field는 하나만 두고, 생성자에서 dictionary를 주입받아 사용하는 방식으로 구현할 수 있다.
public class SpellChecker {
private Lexicon dictionary;
public SpellChecker(Lexicon dictionary) {
this.dictionary = dictionary;
}
...
}
SpellChecker는 단순히 사전이 무엇이든 간에 상관 없이 자신이 가지고 있는 사전을 기반으로 철자를 확인하는 일만 하면 된다.
DI에 대한 예시를 스프링 코드에서 보면 아래와 같다.
@Service
public class ArticleService {
private final ArticleRepository articleRepository;
private final UserService userService;
private final RelationService relationService;
private final ModelMapper modelMapper;
@Autowired
public ArticleService(final ArticleRepository articleRepository,
final UserService userService,
final RelationService relationService,
final ModelMapper modelMapper) {
this.articleRepository = articleRepository;
this.userService = userService;
this.relationService = relationService;
this.modelMapper = modelMapper;
}
}
@RestController
@RequestMapping("/api/articles")
public class ArticleApiController {
private final ArticleService articleService;
@Autowired
public ArticleApiController(ArticleService articleService) {
this.articleService = articleService;
}
}
스프링에서는 @Autowired annotation으로 생성된 빈을 주입해준다. 이 경우엔 싱글 인스턴스를 보장하기 위해 이미 생성되어 컨테이너에 들어있는 빈을 사용하기 위해 DI를 사용한 것 같다.
10/26
- Servlet Container vs. Spring Container(DI Container)
둘다 컨테이너라는 이름을 사용한 것으로 보아 무엇인가를 보관하는 공간인 것 같다.
- Servlet Container(대표적으로 Tomcat)는 서블릿*들의 저장 공간이다.
- 여러 서블릿들의 생명주기 관리, 멀티쓰레드 지원을 한다.
- Spring MVC도 Servlet Container가 관리하고 있는 Servlet이다.
- Spring MVC로의 모든 Request, Response는 DispatcherServlet에서 관리한다.
*서블릿: 자바로 웹을 개발하기 위해 정해진 규약? 인터페이스? JPA같은 느낌이다.
- Servlet Container
서블릿 컨테이너는 개발자가 웹서버와 통신하기 위하여 소켓을 생성하고, 특정 포트에 리스닝하고, 스트림을 생성하는 등의 복잡한 일들을 할 필요가 없게 해준다. 컨테이너는 servlet의 생성부터 소멸까지의 일련의 과정(Life Cycle)을 관리한다. 대표적인 Servlet Container가 Tomcat 이다.
- Http request를 Servlet Container에 보낸다.
- Servlet Container는 HttpServletRequest, HttpServletResponse 객체를 생성한다.
- 사용자가 요청한 URL 분석해서 어느 서블릿 요청인지 찾는다.
- service() 호출 -> doGet() or doPost()
- HttpServletResponse에 응답을 보냄.
- Spring Container (DI Container)
Spring Container는 Bean의 생명주기를 관리한다.
- 웹 애플리케이션이 실행되면 Tomcat(WAS)에 의해 web.xml이 loading된다.
- web.xml에 등록되어 있는 ContextLoaderListener(Java Class)가 생성된다. ContextLoaderListener 클래스는 ServletContextListener 인터페이스를 구현하고 있으며, ApplicationContext를 생성하는 역할을 수행한다.
- 생성된 ContextLoaderListener는 root-context.xml을 loading한다.
- root-context.xml에 등록되어 있는 Spring Container가 구동된다. 이 때 개발자가 작성한 비즈니스 로직에 대한 부분과 DAO, VO 객체들이 생성된다.
- 클라이언트로부터 웹 애플리케이션이 요청이 온다.
- DispatcherServlet(Servlet)이 생성된다. DispatcherServlet은 FrontController의 역할을 수행한다. 클라이언트로부터 요청 온 메시지를 분석하여 알맞은 PageController에게 전달하고 응답을 받아 요청에 따른 응답을 어떻게 할 지 결정만한다. 실질적은 작업은 PageController에서 이루어지기 때문이다. 이러한 클래스들을 HandlerMapping, ViewResolver 클래스라고 한다.
- DispatcherServlet은 servlet-context.xml을 loading 한다.
- 두번째 Spring Container가 구동되며 응답에 맞는 PageController 들이 동작한다. 이 때 첫번째 Spring Container 가 구동되면서 생성된 DAO, VO, ServiceImpl 클래스들과 협업하여 알맞은 작업을 처리하게 된다.
10/25
- JVM에서 GC가 일어날 때 한 트랜잭션이 끝났는지 어떻게 확인하고 Stop-The-World 하는가?
- GC가 돌 때 나머지 Thread들의 상태를 저장하고, GC가 돈다.
- 하지만 Transaction 관점에서 보면, 만약 DB에 insert하는 transaction 중간에 GC가 끼게된다면, timeout이 발생할 가능성은 생긴다.
- GC의 정책이 변경된다고 했을 때 예상치 못한 에러가 발생할 가능성이 있다.
10/22
- JPA FetchType과 프록시 객체
- 프록시는 원본 객체를 상속받아서 만들어진다.
- 영속성 컨텍스트는 영속 엔티티의 동일성을 보장해야한다.
- 처음 조회할 때 프록시 객체였다면, 다음 조회할 때도 프록시 객체가 나와야 한다.(동일성 보장)
@NoArgsConstructor(access = AccessLevel.PRIVATE)
@Getter
@Entity
public class Article extends BaseEntity implements Comparable<Article> {
@Embedded
private ArticleFeature articleFeature;
@OnDelete(action = OnDeleteAction.CASCADE)
@ManyToOne
private User author;
@Enumerated(EnumType.STRING)
private OpenRange openRange;
public Article(ArticleFeature articleFeature, User author, OpenRange openRange) {
this.articleFeature = articleFeature;
this.author = author;
this.openRange = openRange;
}
public void update(ArticleFeature updatedArticleFeature) {
articleFeature = updatedArticleFeature;
}
public boolean isSameUser(User user) {
return this.author.equals(user);
}
@Override
public int compareTo(Article article) {
return this.getUpdatedTime().compareTo(article.getUpdatedTime());
}
}
이 상황에서 ArticleService.findById(Long id) 호출 시 Article이 영속성 컨텍스트에 등록되면서, Article 내부의 author도 영속성 컨텍스트에 들어간다.
현재 코드에서는 ManyToOne이라서 FetchType.EAGER로 동작해서 프록시 객체로 생성되지 않지만, 테스트를 위해 아래와 같이 LAZY로 수정 해본다.
@OnDelete(action = OnDeleteAction.CASCADE)
@ManyToOne(fetch = FetchType.LAZY)
private User author;
그럴 경우 Article 조회 시 User author는 프록시 객체로 1차 캐시에 들어간다. 그 다음에 해당하는 User를 조회해오면 영속성 컨텍스트는 동일성을 보장해야하기 때문에 똑같이 프록시 객체로 조회가 된다.(프록시 타겟의 식별자가 같은) 따라서 이 경우에는 equals를 구현 할 때 IDE에서 자동 생성해주는 equals를 사용하는 것이 아니라 instanceof를 사용해서 비교해야 한다.(프록시는 원본 엔티티의 자식 타입이므로)
- 초기화된 프록시를 비교할 때는 instanceof를 사용, 프록시에 user.id 말고 user.getId()을 사용하자. 프록시의 데이터를 조회할 때는 getter를 쓰자.
10/19 (혼자 알아본 것)
REST는 긴 시간을 거쳐 진화하는 웹 애플리케이션을 위한 것이다.
- REST - How do I improve HTTP without breaking the Web
- 분산 하이퍼미디어 시스템(예: 웹)을 위한 아키텍쳐 스타일(제약조건의 집합)
- Client-Server / Stateless / Cache / Uniform interface / Layered System / Code-on-demand
- Uniform interface - 서버와 클라이언트가 각각 독립적으로 진화하기 위해서.
- 우리의 REST API들을 아래 내용들을 가장 많이 지키지 못하고 있다.
- Self-Descriptive Messages
- 메세지의 내용만으로 메세지가 뭘 하는지 알수 있어야한다.
- HATEOAS
- 애플리케이션의 상태는 Hyperlink를 통해서 전이되어야 한다.
- Self-Descriptive Messages
- REST API는?
- REST 아키텍쳐 스타일을 따르는 API
GET /todos HTTP/1.1
Host: smjeon.dev
HTTP/1.1 200 OK
Content-Type: text/html
<html>
<body>
<a href="https://todos/1">REST 정리하기</a>
<a href="https://todos/2">REST API 정리하기</a>
</body>
</html>
위와 같은 HTML을 보면 self-descriptive, HATEOAS 하다는 것을 알수 있다.
GET /todos HTTP/1.1
Host: smjeon.dev
HTTP/1.1 200 OK
Content-Type: application/json
[
{"id": 1, "title": "REST 정리하기"},
{"id": 2, "title": "REST API 정리하기"}
]
그러나 우리가 구현하는 API의 경우에는 위와 같은 식으로 나오지만, 여기서 json 문서에서 id는 뭐고 title이 무엇인지 확인할 수 없다. HATEOAS 측면에서는 링크가 없어서.. HATEOAS를 만족시킬 수 없다.
- Self-descriptive - 확장가능한 커뮤니케이션
- HATEOAS - 애플리케이션 상태 전이의 late binding, 링크는 동적으로 변경될 수 있다.
GET /todos HTTP/1.1
Host: smjeon.dev
HTTP/1.1 200 OK
Content-Type: application/json
Link: <https://example.org/docs/todos>; rel="profile"
[
{"id": 1, "title": "REST 정리하기"},
{"id": 2, "title": "REST API 정리하기"}
]
이런 식으로 Self-descriptive 를 만족 시킬 수도 있다.
- 참고 자료: 그런 REST API로 괜찮은가
10/18
- 회사에서 업무 진행하면서 기존 레거시 코드에 대한 리팩토링 시간을 따로 가질 수 있을까?
- 팀 바이 팀이겠지만, 따로 리팩토링을 할 시간을 주지는 않는다. 반드시 고치고 싶은 코드들이 있다면 내가 더 노력해서 바꿔보자
- Web server에서 static file을 serving할 때 WAS의 요청과 어떻게 구분할 수 있을까?
- web server 단에서 설정하기 나름이다. (내 생각이지만, 현재는 web server와 was를 모두 내가 구현하기 때문에 일종의 규약 같은게 필요 없지만 팀 단위로 진행되는 프로젝트에서는 일종의 컨벤션처럼 정적파일 서빙에 대한 처리를 규약으로 가지고 있어야 할 것 같다.)
- 그러면 /resource/*에서 찾는 정적파일과 내가 /resourse/test 와 같은 api call을 만들었다면 이 둘을 어떻게 구분할 수 있을까?
10/17
- Java의 Heap은 왜 Heap일까?
- Stack overflow
- Heap 자료구조와는 관련이 없다.
- 위키피디아에서는 Lisp이 Memory store를 구현하기 위해 heap 자료구조를 사용했기 때문에.. 그렇게 됐다.(어떻게 했다고는 나와있지 않다.)
- 메모리 힙은 세탁물 바구니의 heap of clothes와 같은 느낌으로 부른다. 그러니까 메모리가 할당되고 해제되는 messy한 공간을 가리키기 위해 사용된다.
10/16
- Java에서 ArrayList
- ArrayList
- default capacity: 10이다. MAX_ARRAY_SIZE: MAX_INT - 8 이다.
- ArrayList에 add 할 때 공간이 부족하면 현재 있는 값들을 복사하고 add한다.
- 공간이 부족하면 기존 사이즈의 1.5배를 해서 새로운 Array를 만들고 값을 복사한다.
- add에서 동작을 보면 thread-safe 하지 않다.
- ArrayList
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
ArrayList에서 사이즈가 바뀔 때 Object[]이 바뀌는지 확인하기 위한 테스트로 아래와 같은 코드를 수행한다.
@Test
void arrayTest() {
List<Integer> testArrayList = new ArrayList<>();
for (int i = 0; i < 15; i++) {
testArrayList.add(i);
}
}
그리고 ArrayList의 grow 메서드에 break point를 찍고 확인해보면, 볼 수 있다. (사이즈를 지정하지 않으면 default size는 10이다.) 사이즈가 10보다 커질 때 grow method가 실행되는데, grow method가 실행된 후 size는 기존 사이즈의 1.5배만큼으로 늘어난다. (int newCapacity = oldCapacity + (oldCapacity >> 1);) 그러면서 Object array를 늘어난 크기로 새로 만들고 기존 데이터들을 복사한다.
Default Size 10까지는 변화 없이 하나씩 요소들을 추가 한다.
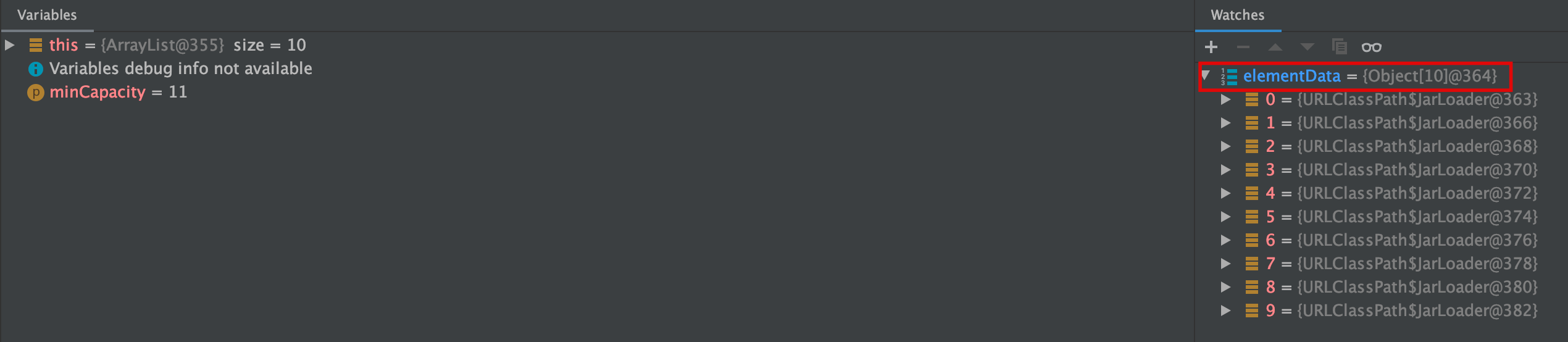
10보다 커지는 순간 grow method가 실행 되면서 새로운 Object array를 만들고 여기에 기존에 값들을 복사한다.
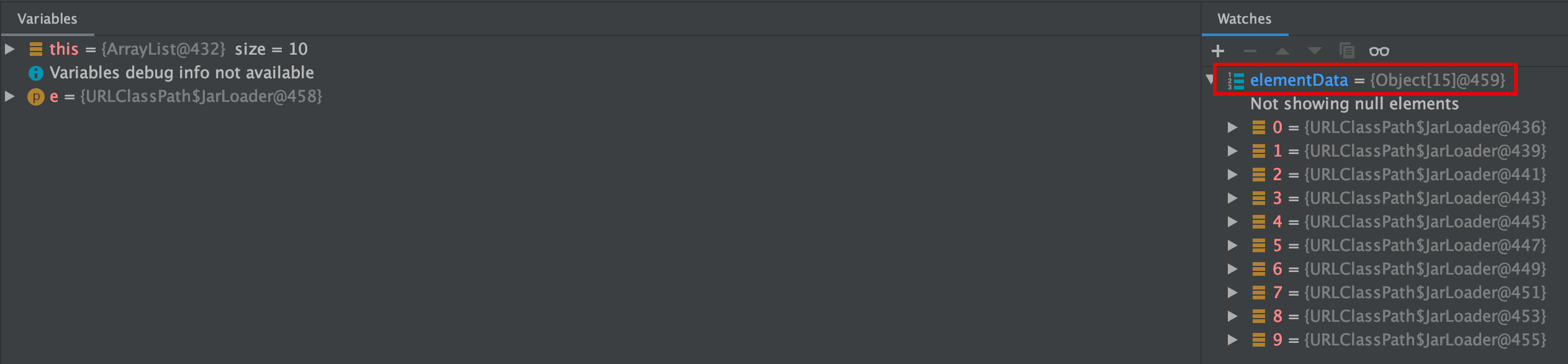
10/15
- Java Stream
- 스트림은 중간 처리 단계(map, filter 같은)와 최종 단계(foreach, reduce 같은)로 구성된다.
- 중간 처리 단계(intermediate) 를 거치면 새로운 스트림이 나온다.(항상 Lazy) 파이프라인의 최종 단계(terminal)가 실행 될 때까지 파이프라인 소스는 시작되지 않는다.
- 최종 단계를 거치면 스트림 파이프라인은 소모되었다고 생각되어서 더이상 쓸 수 없다.
- 동일한 데이터 소스를 다시 통과해야 하면, 데이터 소스에서 새 스트림을 얻어야 한다.
- 최종 단계는 대부분의 경우에 eager다. (iterator(), spliterator()만 아니다)
- Parallelism
- for-loop 처리는 본질적으로 serial 이다.
- stream은 각 개별 요소에 대해 필수 작업 말고, aggregate operation의 파이프라인으로서 계산을 reframing해서 병렬 실행을 용이하게 한다?
- 모든 스트림작업은 직렬 또는 병렬로 실행할 수 있다.
- Collection.stream(): 직렬 스트림, Collection.parallelStream(): 병렬 스트림
- 직렬, 병렬 스트림의 차이는 terminal operation이 시작되면 스트림 파이프라인은 직렬 또는 병렬로 수행된다.
- findAny() 같은 nondeterministic 한 것이 아니면, 직렬인지 병렬인지의 차이는 계산 결과에 영향이 없어야 한다.
- 박싱 주의 (기본형의 경우 IntStream, LongStream, DoubleStream 사용)
- Stream source에 따라 병렬화에 좋을 수도 있고, 좋지 않을 수도 있다.(예를 들어 LinkedList는 분해에 좋지 않다.)
ArrayList<String> results = new ArrayList<>();
stream.filter(s -> pattern.matcher(s).matches())
.forEach(s -> results.add(s));
위 코드에서 ArrayList는 thread-safe하지 않기 때문에 원하는 대로 결과가 나오지 않을 수 있다.(무슨 의미인지 눈으로 확인해본 적이 없어서 잘 모르겠다.) 대신 아래와 같은 코드로 구현하면 안전하다.
List<String>results =
stream.filter(s -> pattern.matcher(s).matches())
.collect(Collectors.toList());
10/14
- Gateway
- 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 컴퓨터나, 소프트웨어.
- 다른 네트워크로 들어가는 입구 역할을 하는 네트워크 포인트
- 서로 다른 네트워크 상의 통신 프로토콜을 적절히 변환해주는 역할을 한다.
- 하나 이상의 프로토콜을 사용하여 통신한다는 면에서 라우터, 스위치와는 다르다.
- 비유하자면 외국인과 원활한 의사소통을 위해 통역사를 두는 것, 통역사(게이트웨이)는 외국인(다른 네트워크)과 소통을 위해 반드시 거쳐야하는 사람. 이라고 할 수 있다.
라우터와 동일한 개념으로 이해할 수 있다.라우터는 패킷을 다른 네트워크로 보내주는 역할을 하면서 최적의 네트워크 경로를 찾아주는 역할을 한다.
로컬 네트워크에는 게이트웨이가 필요 없지만,인터넷과 같은 다른 네트워크에 접근하려면 게이트웨이가 필요하다.
댓글남기기