TIL(3월)
틀린 내용이나 본문의 내용과 다른 의견이 있으시면 댓글로 남겨주세요!
03/27
Javascript Set & WeakSet, Map & WeakMap
WeakSet은 참조를 가진 객체만 저장가능한 Set이다. Set은 중복없이 유일한 값을 저장하려고 할때 사용.
let mySet = new Set();
mySet.add("martin");
mySet.add("value");
mySet.add("martin");
mySet.add("martin");
mySet.delete("martin");
mySet.forEach(value => {
console.log(value);
}); // value 만 나옴
WeakSet은 객체형태를 중복없이 저장하려고 할때 유용하다. WeakSet내의 객체가 다른 참조가 없으면 garbage collection의 대상이 된다.
let arr = [1, 2, 3, 4];
let arr2 = [5, 6, 7, 8];
let obj = {arr, arr2};
let myWeakSet = new WeakSet();
myWeakSet.add(arr);
myWeakSet.add(arr2);
myWeakSet.add(obj);
arr = null;
arr2 = null; // 참조 제거
console.log(myWeakSet);
console.log(myWeakSet.has(arr), myWeakSet.has(arr2), myWeakSet.has(obj)); // false false true
Map은 Key/Value 구조로 저장한다. WeakMap은 Key값이 참조를 가진 객체여야 한다.
let arr = [1, 2, 3, 4];
let arr2 = [5, 6, 7, 8];
let count = 0;
let myFunction = function(){};
let myWeakMap = new WeakMap();
myWeakMap.set(myFunction, count);
for(let i = 0; i < 10 ; i++) {
count = myWeakMap.get(myFunction);
count++;
myWeakMap.set(myFunction, count);
} // myFunction 실행 횟수 저장, 10번 함수 실행됨.
console.log(myWeakMap.get(myFunction)); // 10
myFunction = null; // 참조 제거
console.log(myWeakMap.has(myFunction)); // false
참고자료 (Set, Map)
03/25
Process Synchronization
공유 데이터의 동시 접근 때문에 데이터의 불일치 문제가 발생할 수 있다. 그래서 프로세스 간의 실행 순서를 정해주는 메커니즘이 필요하다.
Race Condition
- Kernel 수행 중 Interrupt 발생시
- Kernel의 data load 이후 인터럽트 발생하여 ISR로 들어갔는데 이 Interrupt handler에서 해당 kernel의 data를 변경할 수 있는 가능성이 있다.
- data load 하고 store 할 때 까지는 인터럽트가 발생하지 않도록 막는 방법이 있다.
- Process가 System call로 kernel mode 인데 context switch가 일어난 경우
- Process가 커널 모드에서 어떤 kernel data를 건드렸는데 이 상황에서 다른 프로세스로 context switching이 발생한 경우.
- Process가 kernel mode일 때는 CPU를 뺏는 일이 발생하지 않도록 막는다.
- Shared memory 내의 kernel data
- 한번에 하나의 CPU만 커널에 들어갈 수 있도록 하는 방법
- Kernel data에 lock을 걸고 푸는 방식
Multi-process 와 Critical Section 의 문제를 해결하기 위한 충족 조건
- Mutual Exclusion
- 어떤 프로세스 A가 Critical Section에 들어가있으면 다른 프로세스는 Critical section에 접근 못하게 막는다.
- Progress
- 아무도 critical section에 없을 때 프로세스가 들어가고자 하면 들어갈 수 있도록 해야한다.
- Bounded Waiting
- critical section에 들어가려는 요청 이후 기다리면 들어갈 수 있도록 해야한다. (starvation이 발생하면 안된다.)
Semaphore
Semaphore 변수가 S라고 하면, P(S)는 자원을 획득하여 사용하는 연산/V(S)는 자원을 반환하는 연산이다. P(S)나 V(S)의 실제 구현은 각자의 구현 방식에 따라 다르게 구현할 수 있다.
Deadlock - 다른 프로세스가 가지고 있는 자원을 무한정 기다리게 되는 일이 일어날 수 있다.
Starvation - 어떤 프로세스가 자원을 무한히 얻지 못할 수 있다.
Synchronization Problem
- Producer-Consumer Problem
- Producer도 Consumer도 공유데이터에 대한 lock을 걸고 푸는 작업이 필요하다.
- 이 공유 데이터가 있는 공유 버퍼가 유한하기 때문에 문제가 된다. 버퍼가 가득 찼는데 Producer가 생산 하려고 한다거나, 버퍼에 아무 데이터도 없는데 Consumer가 버퍼에서 꺼내가려고 하는 지
- Reader-Writer Problem
- 읽는 프로세스와 쓰는 프로세스가 있다고 해보자.
- 쓰는 프로세스가 Write할 때 공유 데이터(DB)에 접근하면 안됨. Read의 경우에는 동시에 DB에 접근해도 됨.
- Writer가 DB에 접근 중이면 Reader와 Writer의 접근을 막는다.
- Reader가 DB에 접근 중이면 Reader는 Read를 할 수 있고, Writer의 경우엔 기다린다.
- 구현 방식에 따라서 Writer의 경우에 Starvation이 발생할 수 있다.
- Reader - Writer - Reader - Reader - Reader… 이런식으로 접근했을 때 2번째 들어온 Writer는 영원히 자원을 얻지 못할 수도 있다.
- 큐에다 우선순위를 두어서 지나치게 늦게 온 Reader는 조금 기다리게 하고 Writer에게 공유 데이터에 대한 접근을 주는 식으로 해결할 수 있나?
- Dining Philosopher Problem
03/23
CPU Scheduler
Ready 상태의 Process 중 이번에 CPU를 줄 프로세스를 고름
Dispatcher - CPU의 제어권을 CPU scheduler에 의해 선택된 프로세스에게 준다.(Context switching)
Scheduling 목적
System의 성능을 향상시키기 위해..(어떤 성능 지표들?)
- CPU Utilization
- Throughput - 단위 시간당 처리할 수 있는 양
- Turnaround time - 들어와서 나갈 때까지의 시간
- Waiting time - Ready 상태에서 기다리는 시간
- Response time - 처음으로 CPU를 얻을 때까지의 시간
Scheduling Criteria
- I/O bound or CPU bound
- Batch or Interactive
- Total service time of process
- Process priority
- Process type, importance
Scheduling 기법들은 FCFS, RR, SPN(Shortest Process Next), SRTN(Shortest Remaining Time Next), HRRN(High Response Ratio Next), Priority, MLQ(Multi-level Queue), MFQ(Multi-level Feedback Queue) 같은 것들이 있다.
03/22
03/21
JS 비동기, callback
일단 비동기라고 하면, callee에 callback 전달, callee 함수의 작업이 완료되면 callback 실행, caller 함수는 작업 완료를 신경쓰지 않음
가장 쉽게 볼 수 있는 사례가 ajax다. 그러니까 서버로 api call 했을 때 이 응답을 기다리는 것이 아니라 다음 코드를 실행하는 것이다. 또다른 사례는 setTimeOut()이다
console.log('A');
setTimeout(function() {
console.log('B');
}, 3000);
console.log('C');
이러면 A -> C -> B 순으로 출력 될 것이다. setTimeOut()이 비동기이므로 순서대로 실행되는데 B를 출력할 때 3초를 기다리는 것이 아니라 일단 다음 코드를 실행하고 3초가 지나면 B를 실행하는 것이다.
그래서 콜백 함수로 비동기의 문제점을 해결 할 수 있다.
function getData(callbackFunc) {
$.get('/articles/1', function(response) {
callbackFunc(response);
});
}
서버로부터 받은 response를 가지고 다음 callback function을 실행할 수 있게 된다. 이 콜백함수들을 막 쓰다보면 인터넷에서 예시로 많이 나오는 콜백 지옥에 빠질 수 있다. 이를 해결하기 위해서 promise나 async를 사용하는 방법이 있다고 한다. 이게 잘 이해가 안되는 이유가 function의 파라미터로 function을 넘긴다는 개념 자체를 이해하기 힘들어서 그런 것 같다.
그래서 일단 Promise에 대해 공부
Promise
Promise는 JS 비동기 처리에 사용되는 객체. Promise는 세 가지 상태가 있다. Pending, Fulfilled, Rejected.
new Promise(); // Pending
new Promise(function(resolve, reject) {
resolve(); // fulfilled
});
new Promise(function(resolve, reject) {
let data = 100;
resolve(data);
}).then(resolvedData => {
console.log(resolvedData);
});
이런 식으로 볼 수 있다.
new Promise(function(resolve, reject){
setTimeout(function() {
resolve(1);
}, 3000);
})
.then(result => {
console.log(result);
return result + 10;
})
.then(result => {
console.log(result);
return result + 100;
})
.then(result => {
console.log(result);
});
위 코드는 3초 뒤에 1, 11, 111이 출력 될 것이다. 이전에 한 프로젝트에서는 다음과 같은 코드를 작성했었다.
createRoom() {
let params = new URLSearchParams();
params.append('gameKind', this.gameKind)
axios.post('/rooms', params)
.then((response) => {
return response.headers;
})
.then((headers) => {
const url = headers.location;
this.$router.push(`/${this.gameKind + url}`);
});
},
그래서 /rooms로 post 요청을 보내고 받은 response에서 header값을 가지고 새로 만든 방의 url로 push 해주는 방식으로 구현했다.
참고자료 (javascript)
03/20
Vue computed, filter
Vue computed - 템플릿의 데이터 표현을 더 직관적이고 간결하게 도와준다. data 값이 변했을때 이를 감지하고 자동으로 다시 연산해준다.
옳은 방식인지는 모르겠지만 지난 프로젝트를 할 때 이런식으로 구현했던 적이 있다.
mounted: function () {
window.setInterval(() => {
this.now = Math.trunc((new Date()).getTime() / 1000);
}, 1000);
eventBus.$on(`initTime`, () => this.limit = Math.trunc((new Date().getTime() / 1000) + Number(this.date)));
},
props: {
date: Number,
roomId: String,
client: {},
day: Boolean,
occupation: String,
dialog: Boolean
},
data() {
return {
now: Math.trunc((new Date()).getTime() / 1000),
limit: Math.trunc((new Date().getTime() / 1000) + Number(this.date))
}
},
computed: {
seconds() {
const time = this.limit - this.now;
if (this.day) {
window.console.log('낮');
if (time === 0) {
this.client.send('/app/rooms/' + this.roomId + '/vote');
}
} else {
window.console.log('밤');
window.console.log(this.dialog);
window.console.log(`time:` + time + `occupation` + this.occupation);
if (time === 0 && this.occupation !== 'SOLDIER' && this.occupation !== 'CITIZEN') {
this.client.send('/app/rooms/' + this.roomId + '/vote');
}
}
return time > 0 ? time : 0;
},
},
limit, now가 변경되므로 변경 될 때마다 seconds()가 갱신되어 time이 0보다 크면 time 출력, 0보다 작으면 0을 출력하게 했다. 그리고 이 컴포넌트가 mount될 때 1000 milisecond 마다 this.now를 갱신하기로 했다. 그리고 data에는 현재 시간과 타이머로 설정한 시간에 대한 값을 넣어놓았다. 그러면 setInterval로 1초 간격으로 now 값이 갱신되기 때문에, data의 값이 변했을 때 computed 는 다시 연산해준다. 그래서 이를 뿌려주는 template에서는 아래와 같다.
<template>
<div>
<div class="block">
<p class="digit"></p>
</div>
</div>
</template>
그래서 타이머가 1초 간격으로 바뀌면서 화면에 출력된다. 이런식으로 Timer.vue component를 완성했다. 예전에 대충 인터넷에서 보고 따라했던 개념을 조금 이해했다.
여기에는 filter 개념도 들어있는데, 전역 필터로 다음과 같이 등록해두었다. 단순히 0~9까지의 시간이 남았을 때에도 00~09로 표현하도록 한 필터이다. 필터는 실제로 화면에 포시되는 텍스트의 형식을 쉽게 변환하는 용도로 사용한다. 내가 했던 프로젝트에서는 filter가 한개 뿐이라 단순하게 등록했지만, 여러 필터가 존재할 경우 filter.js라는 파일로 분리하여 해당 파일에서 필터들을 읽어와 넣어주는 작업을 할 수 있다.
Vue.filter('two_digits', function (value) {
if (value.toString().length <= 1) {
return "0" + value.toString();
}
return value.toString();
});
03/19
javascript에서 this
console.log(this); // window
let obj = {
num: 10,
print: function() {
console.log(this); // 객체 그대로
console.log(this.num); // 10
}
};
obj.print(); // 객체 obj {num: 10, print: f} 이런 것들, 10
function print() {
console.log(this);
}
print(); // window
function Test() {
console.log(this);
}
let temp = new Test(); // Test {}
function fetchData() {
axios.get('/articles').then(function() {
console.log(this);
});
}
fetchData(); // window, 비동기 처리 코드의 콜백 함수는 전역 컨텍스트를 가리킨다
자바스크립트의 경우 함수 호출 방식에 의해 this에 바인딩할 어떤 객체가 동적으로 결정된다. 다시 말해, 함수를 선언할 때 this에 바인딩할 객체가 정적으로 결정되는 것이 아니고, 함수를 호출할 때 함수가 어떻게 호출되었는지에 따라 this에 바인딩할 객체가 동적으로 결정된다.
var foo = function () {
console.dir(this);
};
// 1. 함수 호출
foo(); // window
// window.foo();
// 2. 메소드 호출
var obj = { foo: foo };
obj.foo(); // obj
// 3. 생성자 함수 호출
var instance = new foo(); // instance
// 4. apply/call/bind 호출
var bar = { name: 'bar' };
foo.call(bar); // bar
foo.apply(bar); // bar
foo.bind(bar)(); // bar
기본적으로 this는 전역객체(Global object)에 바인딩된다. 전역함수는 물론이고 심지어 내부함수의 경우도 this는 외부함수가 아닌 전역객체에 바인딩된다.
function foo() {
console.log("foo's this: ", this); // window
function bar() {
console.log("bar's this: ", this); // window
}
bar();
}
foo();
또한 메소드의 내부함수일 경우에도 this는 전역객체에 바인딩된다.
var value = 1;
var obj = {
value: 100,
foo: function() {
console.log("foo's this: ", this); // obj
console.log("foo's this.value: ", this.value); // 100
function bar() {
console.log("bar's this: ", this); // window
console.log("bar's this.value: ", this.value); // 1
}
bar();
}
};
obj.foo();
함수가 객체의 프로퍼티 값이면 메소드로서 호출된다. 이때 메소드 내부의 this는 해당 메소드를 소유한 객체, 즉 해당 메소드를 호출한 객체에 바인딩된다.
var obj1 = {
name: 'Lee',
sayName: function() {
console.log(this.name);
}
}
위에서처럼 sayName이라는 프로퍼티로 function()을 가지고 있으므로 해당 function 내부의 this는 이 프로퍼티를 가지고 있는 obj1 객체가 된다.
그래서 아래와 같은 결과가 나온다.
var obj2 = {
name: 'Kim'
}
obj2.sayName = obj1.sayName;
obj1.sayName(); // 'Lee'
obj2.sayName(); // 'Kim'
프로토타입 객체도 메소드를 가질 수 있다. 프로토타입 객체 메소드 내부에서 사용된 this도 일반 메소드 방식과 마찬가지로 해당 메소드를 호출한 객체에 바인딩된다.
라고 하는데 프로토타입 객체가 아직 뭔지 모르겠어서 이해가 안된다.
// 생성자 함수
function Person(name) {
this.name = name;
}
var me = new Person('Lee');
console.log(me); // Person {name: "Lee"}
// new 연산자와 함께 생성자 함수를 호출하지 않으면 생성자 함수로 동작하지 않는다.
var you = Person('Kim');
console.log(you); // undefined
일반 함수를 호출하면 this는 전역객체에 바인딩되지만 new 연산자와 함께 생성자 함수를 호출하면 this는 생성자 함수가 암묵적으로 생성한 빈 객체에 바인딩된다.
생성자 함수를 new 없이 호출한 경우, 함수 Person 내부의 this는 전역객체를 가리키므로 name은 전역변수(window)에 바인딩된다. 또한 new와 함께 생성자 함수를 호출하는 경우에 암묵적으로 반환하던 this도 반환하지 않으며, 반환문이 없으므로 undefined를 반환하게 된다.
생성자 함수로 선언된 함수를 new 키워드 없이 호출한 you라는 친구는 함수 Person내의 this가 전역 객체 window를 뜻하므로 window.name에 ‘Kim’이 들어간다.
그러면 생성자 함수를 다음과 같이 수정하면 어떻게 될까?
function Person(name) {
this.name = name;
return this;
}
생성자 함수는 암묵적으로 this를 return 하므로 명시적으로 써준 것이 차이는 없어보인다. 당연하지만 new 키워드 없이 호출했으므로 this가 전역객체(window)이므로 console.log(you) === console.log(window) 이다. 이상한 질문에 당연한 답이 나왔다;
ES6
let & const
let은 한번 선언하면 재선언할 수 없다. 그래도 block scope라 function 내부에 동일한 이름으로 선언하면 해당 scope내에서 사용가능하다(예상대로 동작한다).
let a = 10;
function test() {
let a = 500;
console.log(a);
}
test(); // 500
let a = 20; // Uncaught SyntaxError: Identifier 'a' has already been declared
const는 상수 같은 느낌이다. 한번 할당한 값을 변경할 수 없다. 객체나 배열로 선언했을 때 객체의 속성이나, 배열의 요소는 바꿀 수 있다.
const a = {
test: 1,
s: 'hello world'
};
console.log(a.test); // 1
a.test = 2;
console.log(a.test); // 2
Arrow function
// 매개변수 지정 방법
() => { ... } // 매개변수가 없을 경우
x => { ... } // 매개변수가 한 개인 경우, 소괄호를 생략할 수 있다.
(x, y) => { ... } // 매개변수가 여러 개인 경우, 소괄호를 생략할 수 없다.
// 함수 몸체 지정 방법
x => { return x * x } // single line block
x => x * x // 함수 몸체가 한줄의 구문이라면 중괄호를 생략할 수 있으며 암묵적으로 return된다. 위 표현과 동일하다.
() => { return { a: 1 }; }
() => ({ a: 1 }) // 위 표현과 동일하다. 객체 반환시 소괄호를 사용한다.
() => { // multi line block.
const x = 10;
return x * x;
};
일반 function과 arrow function의 가장 큰 차이점은 this 라고 한다.
자바스크립트의 경우 함수 호출 방식에 의해 this에 바인딩할 어떤 객체가 동적으로 결정된다. 다시 말해, 함수를 선언할 때 this에 바인딩할 객체가 정적으로 결정되는 것이 아니고, 함수를 호출할 때 함수가 어떻게 호출되었는지에 따라 this에 바인딩할 객체가 동적으로 결정된다.
Arrow Function은 함수를 선언할 때 this에 바인딩할 객체가 정적으로 결정된다. 동적으로 결정되는 일반 함수와는 달리 화살표 함수의 this 언제나 상위 스코프의 this를 가리킨다. 이를 Lexical this라 한다.
참고 자료 (ES6)
03/16
SOLID
- Single Responsibility Principle
- 모든 클래스는 하나의 책임만을 가지며, 그 클래스는 책임을 완전히 캡슐화 해야 한다. 어떤 클래스나 모듈은 변경하려는 단 하나의 이유만을 가져야 한다.
- Open Close Principle
- 확장에는 열려있으며, 수정에 대해서는 닫혀있어야 한다.
- Liskov Substitution Principle
- 상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다.
- Vehicle car1 = new Car(), Vehicle car2 = new Truck() 에서 car1.run() 과 car2.run()이 같은 성격의 동작을 해야한다.
- Interface Segregation Principle
- 인터페이스는 최대한 작은 조각으로 쪼개라 -> 자신이 사용하는 인터페이스들만 구현해라?
- Dependency Inversion Principle
- 하위 레벨 모듈의 변경이 상위 레벨 모듈의 변경을 요구하지 않도록 해야한다.
- 의존관계를 맺을 때 변하기 쉬운 것보다 변하기 어려운 것에 의존관계를 맺어라
- 인터페이스를 끼고 의존 관계를 맺자
트랜잭션의 목적
데이터베이스 기능 중, 트랜잭션을 조작하는 기능은 사용자가 데이터베이스 완전성 유지를 확신하게 한다.
단일 트랜잭션은 데이터베이스 내에 읽거나 쓰는 여러 개 쿼리를 요구한다 이때 중요한 것은 데이터베이스가 수행된 일부 쿼리가 남지 않는 것이다. 예를 들면, 송금을 할 때 한 계좌에서 인출되면 다른 계좌에서 입금이 확인되는 것이 중요하다. 또한 트랜잭션은 서로 간섭하지 않아야 한다.
03/14
데이터베이스
데이터베이스를 사용하는 이유 - 파일 시스템을 사용했던 것의 한계를 극복하기 위해
장점 - 데이터 독립성, 무결성, 보안성, 일관성, 중복 최소화
데이터베이스 인덱스
인덱스는 데이터베이스에서 테이블에 대한 동작 속도를 높여주는 자료구조이다. 테이블 내의 1개 이상의 컬럼을 이용해서 생성할 수 있다. 특정 데이터를 검색하기 위해서 테이블의 레코드를 풀스캔하는 것이 아니라, 인덱스가 적용된 컬럼의 테이블을 따로 파일로 저장해놓고 그 파일을 검색한다.
InnoDB에서는 항상 clustered index를 가져야함(PK는 항상 clustered index, unique index로 정의된 컬럼 중 하나, 보이지 않는 컬럼을 내부적으로 추가하여 사용)
Clustered Index - 인덱스를 매칭시키기 위해서 데이터 블럭을 분명한 순서로 바꾼다. Clustered index는 read 속도를 향상 시킨다.
Non-Clustered Index - 데이터는 임의의 순서, 논리적 순서는 인덱스에 의해 지정됨. row의 물리적 순서는 인덱스 순서와 동일하지 않다.
DBMS 의 인덱스는 항상 정렬된 상태를 유지하기 때문에 원하는 값을 탐색하는데는 빠르지만 새로운 값을 추가하거나 삭제, 수정하는 경우에는 쿼리문 실행 속도가 느려진다. 사용하지 않는 인덱스는 제거하자. 카디널리티가 높은 칼럼에 인덱스를 생성해주는 것이 좋다. 흔히 사용하는 인덱스는 B-tree 인덱스다.
인덱스가 생성되면 테이블과 매핑된 또다른 테이블이 생성된다고 생각하면 좋다. 인덱스 컬럼을 기준으로 sorting되어 저장된다. 특정 조건에 대해 검색을 한다고 하면 시작점을 지정해서 거기서부터 스캔(Index Range Scan)을 할 수 있다고 생각하면 됨. 인덱스에서 먼저 데이터를 찾고 그 테이블로 매핑된 곳을 가서 나머지 데이터들을 꺼내오는 방식. 인덱스가 해당 테이블 블럭의 주소를 가지고 있다고 생각하면 된다.
Where절에 자주 등장하는 컬럼, Order By절에 자주 등장하는 컬럼을 인덱스로 구성하면 좋다. 그렇다고 마구잡이로 인덱스를 생성하면 안된다. 테이블이 가지고 있는 전체 데이터 양의 10에서 15프로 일때 효율적이고 그 이상일 떈 풀스캔이 더 빠르다.(?)
03/13
암호화, HTTPS, MyISAM과 InnoDB
Hash, 단방향 암호화
평문을 암호문으로 바꾸는 것은 가능하지만, 암호문을 평문으로 복호화하는 것은 불가능한 방식
단순하게 생각하면 필요 없을 것 같지만, 비밀번호 같은 곳에 쓸 수 있다. SHA256 같은 기법들이 있다. 특정 입력값에 대해 똑같은 출력이 나온다. 해싱을 적용한다고 해서 보안상으로 완벽하진 않다. 결국에는 특정한 비트수로 변환이 되는 것이기 때문에, 입력값이 다르더라도 출력값이 같은 경우가 나올 수도 있다.
양방향 암호화
암호화와 복호화가 모두 가능한 알고리즘이다. 대칭키와 비대칭키 방식으로 나누어지는데, 대칭키 방식은 암호화와 복호화에 동일한 키를 사용하고 비대칭키 방식은 암호화와 복호화에 다른 키를 사용한다. 비대칭키 방식은 공개키와 개인키를 가지고 암호화, 복호화를 한다. SSL에서 공개키 암호화 방식을 채택하고 있다. 송신하는 측은 수신하는 측의 공개키를 사용해서 암호화해서 보내고 이 암호문을 수신측에서는 자신의 비밀키를 사용해서 복호화한다. 공개키를 이용해서 암호화 한 것을 복호화 하는 것은 소인수 분해 문제의 해결 방법을 알아내는 것(NP문제를 해결하는 것이므로 불가능하다고 할 수 있다, 사실 이 소인수분해 문제를 해결한다면 이 세상에서 엄청나게 많이 사용하고 있는 암호화 알고리즘이 깨지는 것이기 때문에 엄청난 문제가 될 수 있다.)
HTTP vs. HTTPS
HTTP는, 평문 통신이기 때문에 도청 가능, 통신 상대를 확인하지 않기 때문에 위장 가능, 완전성을 증명할 수 없기 때문에 변조 가능 이라는 단점이 있다.
HTTPS = HTTP + 통신의 암호화 + 증명서 + 완전성 보호
처음 통신에서는 공개키 암호방식으로 공통키를 교환하고, 공통키 암호로 통신을 한다.
그러나 공통키가 중간에 바꿔치기 당했는지는 어떻게 증명 할까? -> 이를 위해서 인증 기관(CA: Certificate Authority)과 공개키 증명서가 이용되고 있다. 유명한 인증기관에는 VeriSign이 있다.
인증 기관은 다음과 같이 이용된다.
- 서버의 운영자가 인증 기관에 공개키를 제출
- 인증 기관은 제출된 공개키에 디지털 서명을 하고 서명이 끝난 공개키를 만든다.
- 공개키 인증서에 서명이 끝난 공개키를 담는다.
- 서버는 이 공개키 인증서를 클라이언트에 보내고 공개키 암호로 통신을 한다.
- 공개키 인증서를 받은 클라이언트는 증명 기관의 공개키를 사용해서 서버의 공개키를 인증한 것이 CA라는 것과 서버의 공개키가 신뢰할 수 있다는 것을 알 수 있다.
MyISAM vs. InnoDB
MySQL 5.5.5 버전 이후로는 default engine이 InnoDB이다.
| MyISAM | InnoDB |
|---|---|
| Foreign key 미지원 | Foreign key 지원 |
| Full Text Search 지원 | MySQL 5.6 이후로는 Full Text Search 지원 |
| Table 단위 lock | Row 단위 lock |
| Data Cache 미지원 | Data Cache 지원 |
| Index Cache 지원 | Index Cache 지원 |
| Clustered Index 미지원 | Clustered Index 지원 |
| Transaction 미지원 | Transaction 지원 |
인터넷의 블로그에는 InnoDB가 Full Text Search 미지원이라고 나와있는데.. 일단 MySQL의 문서에는 5.6 버전 이후에는 지원한다고 나와있다.
참고 - 많은 인터넷의 블로그들과, MySQL 문서 - MyISAM, MySQL 문서 - InnoDB
03/12
Synchronous, Asynchronous I/O, Thread, Scheduling level
Synchronous
사용자 프로세스가 입출력 요청을 한 다음에 아무것도 못하고 기다리고 있다.
Asynchronous
입출력 요청 한 다음에 입출력 진행 되는 동안에 그 프로세스가 다음 instruction을 수행할 수 있다.
Thread
Process 내부에서 공유할 수 있는 건 다 공유하지만 CPU를 더 유용하게 쓰기 위해서 나누어진 단위라고 생각하면 편하다.
Program Counter, Register Set, Stack를 각각 가지고 있고, Code, Data, OS Resource를 Thread끼리 공유한다.
여러 쓰레드를 사용하면.. 하나의 쓰레드가 blocked 상태인 동안에도 동일 프로세스 내의 다른 쓰레드가 running 상태로 더 빠르게 처리할 수 있다. 병렬성을 높일 수 있다. 그러니까 큰 크기의 파일을 읽어오는 작업을 하고 있는 쓰레드가 있는 동안에도 다른 쓰레드는 다른 작업을 해서 성능 향상을 볼 수 있다.
Scheduling level
우리가 하루의 일정을 짜듯 resource들의 스케줄을 짠다고 생각하면 됨.
- Long-term scheduling (Job scheduler)
- 시작 프로세스 중 어떤 것들을 ready queue로 보낼지 결정
- 프로세스에 메모리(각종 자원들)를 주는 문제
- 프로세스가 처음 생성 된 후(created) 메모리를 얻어 ready 상태로 보내는 것을 결정
- degree of multiprogramming을 제어(메모리에 프로그램이 얼마나 올라갈지..)
- time sharing system에는 보통 없다.(무조건 ready 상태로)
- Short-term scheduling (CPU scheduler)
- 어떤 프로세스를 다음번에 running 시킬지 결정
- 프로세스에 CPU를 주는 문제
- Medium-term scheduling
- 여유 공간 마련을 위해서 프로세스를 통째로 메모리에서 디스크로 쫓아낸다.
- 프로세스에게서 메모리를 뺏는 문제
- degree of multiprogramming을 제어
- 얘를 통해 memory를 뺏긴 애들이 suspended ready, suspended blocked 이런 상태로 넘어간다.
03/11
Process
프로세스의 Context
- CPU 수행 상태를 나타내는 hardware context
- Program counter
- 각종 register
- 프로세스의 주소 공간
- Code, Data, Stack
- 프로세스 관련 커널 자료 구조
- PCB
- Kernel Stack
Process State
- Running - CPU를 사용하고 있는 상태(Instruction을 수행중인 상태)
- Ready - CPU를 기다리고 있는 상태(CPU를 제외한 모든 자원은 충족한 상태)
- Blocked (wait, sleep) - CPU 자원이 있더라도 instruction을 수행할 수 없는 상태. I/O를 기다리고 있다거나.. (큰 파일을 읽을 때?)
- Created - 프로세스가 생성중인 상태. (PCB 할당, 커널은 메모리가 여유있는지 확인하고 Ready나 Suspended Ready 상태로 바뀐다, Unix에서 fork()라는 시스템 콜에 의해 생성된다.)
- Terminated - 수행이 끝난 상태
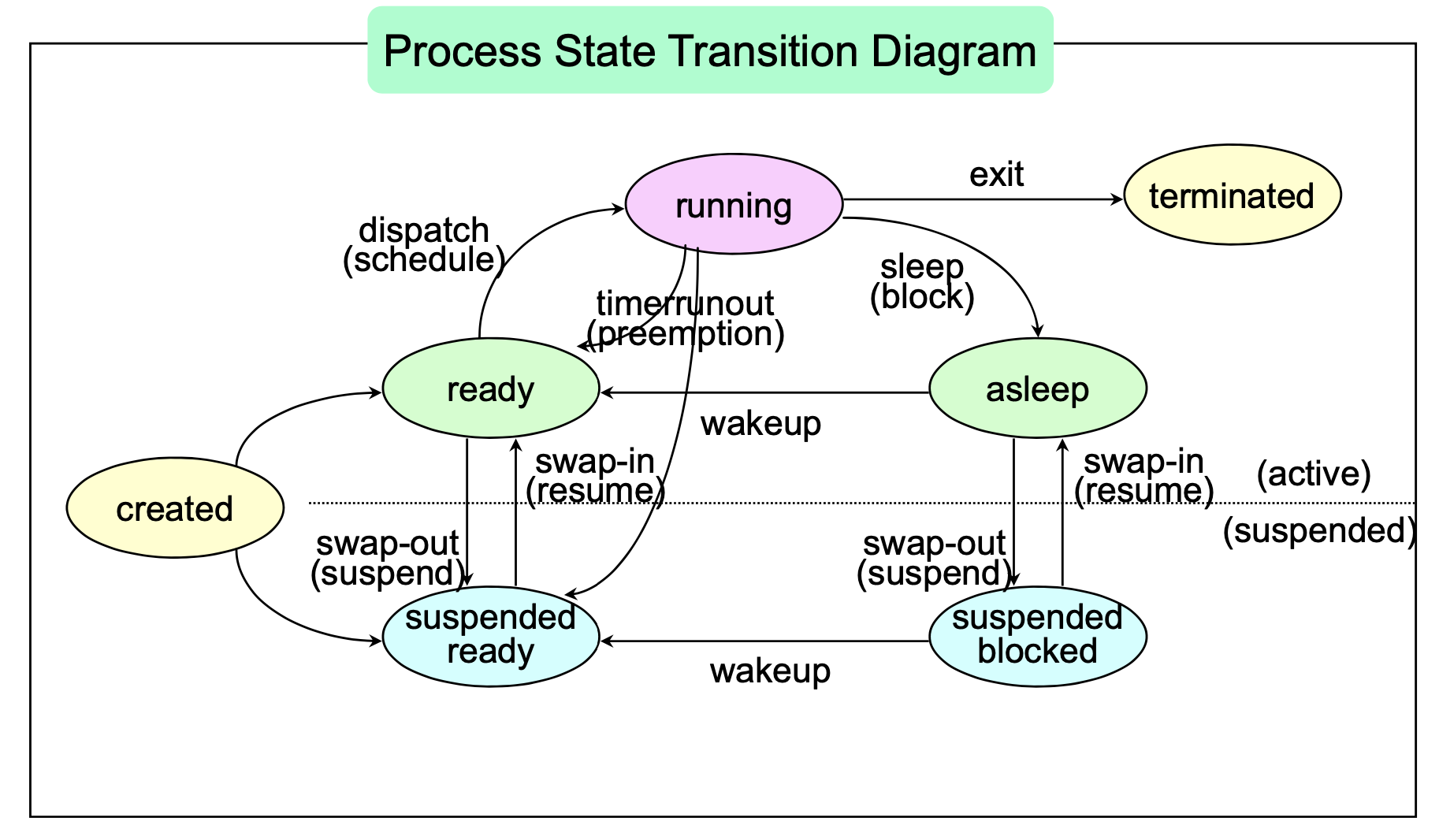
suspended 상태는 메모리에서 내려간 상태라고 생각하면 될듯(사용자가 프로그램을 일시정지, 시스템이 프로세스를 잠시 중단시키는 경우 등)
외부에서 다시 시작해주어야 Active 쪽으로 올라갈 수 있다. 반면에 Blocked 상태는 본인이 요청한 어떤 이벤트(I/O라던가..)가 완료되면 Ready 상태가 된다.
Context Switch
CPU를 한 프로세스에서 다른 프로세스로 넘겨주는 과정, CPU가 다른 프로세스에게 넘어갈 때
- CPU를 내어주는 프로세스의 상태를 그 프로세스의 PCB에 저장
- CPU를 새롭게 얻는 프로세스의 상태를 PCB에서 읽어옴
댓글남기기