TIL(1월) - 2
틀린 내용이나 본문의 내용과 다른 의견이 있으시면 댓글로 남겨주세요!
TIL의 포스팅 길이가 과도하게 길어져 나누어서 포스팅 합니다.
01/20
Tree
트리는 스택이나 큐와 같은 선형 구조가 아닌 비선형 자료구조이다. 트리는 계층적 관계(Hierarchical Relationship)을 표현하는 자료구조이다.
Binary Tree
각각의 노드가 최대 두개의 자식 노드를 가지는 트리, 루트 노드 부터 시작해서 모든 서브 트리들이 binary tree를 만족한다.(그렇게 하기 위해서는 맨 마지막 leaf node들은 null인 2개의 자식 노드를 가지고 있음)
Binary Search Tree
각 노드에 값(A)이 있고, 해당 노드의 왼쪽 자식은 해당 노드의 값(A)보다 작고 오른쪽 자식은 그 값(A)보다 크다. 모든 노드에 대해 이진 탐색 트리를 만족한다. 루트로부터 시작해서 모든 서브 트리들은 이진 탐색 트리를 만족한다.
이진 탐색 트리에서 A라는 값을 가진 노드를 검색한다. 그러면 루트 노드로부터 값이 일치하는지 확인한다. 일치한다면 해당 노드를 반환, 찾으려는 값이 더 작으면 왼쪽 자식을 검사, 더 크면 오른쪽 자식을 검사한다. 이 후로 동일한 로직이 반복된다. leaf node까지 탐색했는데 찾지 못했을 경우 해당 값은 트리에 존재하지 않는다.
삽입의 경우에는 먼저 검색을 한다.(O(logN)) 검색 한 후 노드의 값이 일치하는 노드가 없으면, 마지막 노드에서 크기 비교 후 맞는 위치에 노드를 삽입한다.
삭제의 경우에도 먼저 검색한다.
- 해당 노드가 leaf node 인 경우 - 그냥 삭제한다.
- 자식이 1개인 노드 - 해당 노드를 삭제하고 자식 노드를 그 위치로 올린다.
- 자식 노드가 2개인 노드 - 해당 노드를 삭제하고 왼쪽 자식 중 제일 큰 노드 또는 오른쪽 자식 중 제일 작은 노드를 그 위치로 올린다.
이진 탐색 트리의 경우 일반적인 경우에 시간 복잡도가 O(logN)이지만(트리의 높이만큼이라 사실 O(h)라고 할 수 있다.) worst case의 경우엔 O(N) 까지 생각할 수 있다.(worst case는 한쪽으로 쭉 치우쳐진 이진탐색트리) 그렇기 때문에 이진 탐색 트리의 균형을 맞추는 특별한 규칙을 따르는 자료구조들이 있다.
이진 탐색 트리 중 Red-Black tree나 AVL tree와 같은 특별한 규칙을 따르는 이진 탐색 트리가 있고, 해당 트리에서는 삽입, 삭제의 경우에 트리의 균형을 맞춰주는 balancing이 필요하다.(이러한 balancing 과정은 부모 자식간의 관계만 바꾸는 것이기 때문에 O(1)이다) 결과적으로 삽입, 삭제의 worst case에도 O(logN)을 유지할 수 있다.
01/18
Spring Framework 입문
IoC (Inversion Of Control)
일반적으로 어플리케이션을 작성하면, 이 어플리케이션의 흐름을 제어하는 것은 어플리케이션 코드이다. 그러나 Spring 기반의 개발에서는 프레임워크가 흐름을 제어하는 주체가 된다.
스프링에서 빈들의 생성 부터 생명주기 까지 책임지고 관리한다. 그렇게 함으로써 개발자는 도메인의 핵심 비즈니스 로직에 더 집중할 수 있게 된다.
IoC Container - Bean을 만들고 엮어주며 제공해준다.(이름/ID, Type, Scope)
Bean
스프링 IoC Container가 관리하는 객체
어떻게 등록하지? - Component Scan(@Component, @Repository, @Service, @Controller …)
어떻게 꺼내쓰지? - @Autowired(생성자 주입을 사용할 때 생성자가 하나인 경우 Autowired를 생략할 수도 있다.), @Inject, ApplicationContext에서 getBean을 통해 직접 꺼낼 수도 있다.
AOP
class A {
method a() {
AAAA
치킨을 먹는다.
BBBB
}
method b() {
AAAA
삼겹살을 먹는다.
BBBB
}
}
class B {
method c() {
AAAA
공부를 하고, 면접을 본다.
BBBB
}
}
위와 같은 중복 로직을 AOP를 통해 제거할 수 있다.
class AAAABBBB {
method aaaabbbb(JoinPoint point) {
AAAA
point.execute()
BBBB
}
}
대표적인 사례로는 트랜잭션 처리(부가기능)가 있다. 사실 트랜잭션이라는 기능은 비즈니스 로직과는 관련없이 데이터베이스와 관련된 로직이다. 이 트랜잭션 처리 로직이 비즈니스 로직과 함께 있다면, 이 트랜잭션을 처리하는 기술, 즉 InfraStructure의 기술에 종속되는 코드가 되어버린다. 그렇기 때문에 AOP를 통해 비즈니스 로직과 트랜잭션 로직을 분리하고 있다.
여러 가지 용어들이 있는데, 이 용어들은 다음에 공부할 예정이다.(어드바이스, 포인트컷, 어드바이저)
스프링의 AOP는 프록시를 통해 AOP를 구현하고 있다.(JDK dynamic proxy, CGLib proxy)
JDK dynamic proxy는 인터페이스를 이용하여 구현한다. JDK 다이나믹 프록시는 타겟 오브젝트가 인터페이스를 구현하고 있어야 만들어질 수 있다.
CGLib 프록시는 타겟 클래스를 상속하는 클래스를 만들어서 이 클래스를 프록시로 사용한다. 타겟 클래스를 상속하는 클래스는 타겟 클래스의 모든 메서드를 상속받아 프록시로 사용한다. 그래서 AOP를 적용할 때 위에서 언급한 AAAA, BBBB라는 부분을 프록시 객체의 메서드를 만들 때 사이에 AAAA, 원래 메서드, BBBB 순으로 만들어서 AOP를 구현한다.
01/17
DIP (Dependency Inversion Principle)
고수준 모듈이 저수준 모듈을 사용하면 두 가지 문제(구현 변경과 테스트가 어려움)가 발생한다. DIP는 이 문제를 해결하기 위해 저수준 모듈(인프라)이 고수준 모듈(도메인)에 의존하도록 바꾼다.
DIP를 잘못 생각하면 단순히 인터페이스와 구현 클래스를 분리하는 정도로 받아들일 수 있다. DIP의 핵심은 고수준 모듈이 저수준 모듈에 의존하지 않도록 하기 위함이다. 단순하게 인프라스트럭쳐 레이어의 구현 클래스를 인터페이스로 분리하라는 말이 아니다. DIP를 적용할 때 하위 기능을 추상화한 인터페이스는 고수준 모듈 관점에서 도출한다. 도메인 입장에서 봤을 때 어떤 규칙을 사용하는지, 뭐 직접 계산하는지는 중요하지 않다. 어떤 주어진 규칙에 따라 계산을 하는 것이 중요하다.
책에 나온 예시를 살펴보면,
public interface RuleDiscounter {
public Money applyRule(...);
}
public class SomeRuleDiscounter implements RuleDiscounter {
...
@Override
public Money applyRule(...) {
...
}
}
이런식으로 볼 수 있는데, 이를 사용하는 서비스 레이어에서는 어떤 규칙을 사용해서 할인을 하는 것은 중요하지 않고, 주어진(주입받는) 규칙에 따라(여기서는 SomeRuleDiscounter) 할인을 적용하는 것이다. 그래서 SomeRuleDiscounter의 저수준 모듈이 RuleDiscounter라는 할인을 계산하기 위한 고수준 모듈에 의존하여 infra와 application layer간의 결합도를 낮출 수 있다. 원래 도메인 레이어가 인프라 레이어에 의존할 때 발생하던 구현 교체가 어렵다와 테스트가 어렵다 라는 문제를 해결 할 수 있게 된다.(주입하는 구현체를 교체하는 방식으로, 테스트에서는 테스트용 구현체를 만든다거나..) 동일한 의미인지는 모르겠지만, 전략패턴이 이와 같은 이점이 있었다. 전략패턴의 구현 방식이 DIP를 이해하는데 도움이 되는 것 같다.
이 문제에서 infrastructure layer의 모듈을 추상화하는데, 저수준 모듈 관점/고수준 모듈 관점에서 각각 인터페이스를 추출할 수 있다. 위에 나온 코드처럼 도메인 영역에서의 어떤 규칙이 중요한게 아니라, 어떤 규칙을 적용해서 할인 금액을 계산한다는 로직 관점에서 인터페이스를 추출할 경우엔 올바른 DIP이다.
01/16
DDD Start 1-2장
도메인 모델 - 특정 도메인을 개념적으로 표현한 것이다. 기본적으로 도메인 자체를 이해하기 위한 개념 모델이다. 개념 모델을 이용해서 바로 코드를 작성할 수 있는 것은 아니기에 구현 기술에 맞는 구현 모델이 따로 필요하다.
아키텍처 구성
| 계층 | 설명 |
|---|---|
| Presentation | 사용자의 요청 처리 / 정보를 보여줌 - 소프트웨어 사용자 뿐 아니라 외부 시스템도 사용자가 될 수 있다. |
| Application | 사용자 요청한 기능 실행, 비즈니스 로직을 구현하지 않고 도메인 계층을 조합하여 요청 실행 |
| Domain | 시스템이 제공할 비즈니스 로직을 구현 |
| Infrastructure | 데이터베이스나 메시징 시스템과 같은 외부 시스템과의 연동을 처리 |
도메인을 모델링할 때 기본이 되는 작업은 모델을 구성하는 핵심 구성요소, 규칙, 기능을 찾는 것이다.(요구사항에서 출발한다.)
문서화 - 문서화를 하는 주된 이유는 지식을 공유하기 위함이다. 사실 실제 구현은 코드에 다 나와있지만, 분석하려면 많은 시간이 걸리기 때문에 전반적인 기능 목록이나 모듈 구조, 빌드 과정은 코드를 보고 직접 이해하는 것보다 상위 수준에서 정리한 문서를 참조하는 것이 빠르고 도움이 된다.
엔티티와 밸류
엔티티의 가장 큰 특징은 식별자를 갖는다는 것이다. 엔티티를 생성하고 엔티티의 속성을 바꾸고 엔티티를 삭제할 때까지 식별자는 유지된다. 식별자는 바뀌지 않고 고유하기 때문에, 이 식별자로 두 엔티티가 동일한지 판단할 수 있다. 그래서 엔티티에는 다음과 같이 equals(), hashCode()를 구현할 수 있다.
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Article article = (Article) o;
return Objects.equals(id, article.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
엔티티의 식별자 생성은 보통 다음 중 한 가지 방식으로 생성한다.
- 특정 규칙에 따라 생성
- UUID 사용
- 직접 입력
- DB의 Auto Increment
밸류 타입은 개념적으로 완전한 하나를 표현할 때 사용한다. 예를 들어, 구현 코드에서 살펴보면 다음과 같다.
@Embeddable
public class ArticleForm {
private String title;
@Lob
private String content;
private ArticleForm() {
}
...
}
@Embeddable
public class BasicArticleForm {
@Embedded
private ArticleForm articleForm;
@JoinColumn(name = "author")
@ManyToOne
private User author;
private BasicArticleForm() {
}
...
}
내용의 일부는 생략했다. ArticleForm이라는 밸류 타입으로 게시글에 필요한 title, content를 표현했다. ArticleForm이라는 클래스 그 자체로 게시글 폼을 받을 수 있도록 표현할 수 있다. 또 다른 예를 들어 책에 나와있는 예시를 보면 Address 밸류 타입은 다음과 같이 표현할 수 있다.
public class Address {
private String address1;
private String address2;
private String zipCode;
}
밸류가 꼭 두개 이상의 필드를 가질 필요는 없고, 우리가 전에 사용해봤던 LottoNumber와 같은 클래스들도 코드를 이해하는데 도움을 줄 수 있다. 한 가지 예시로 UserName Class를 만들었다.
@NoArgsConstructor
@Getter
@EqualsAndHashCode(of = "name")
@Embeddable
public class UserName {
@Column(nullable = false, length = 25)
private String name;
public UserName(String name) {
this.name = name;
}
}
위와 같이 UserName 밸류 타입을 만들어서 사용하면서 또 다른 장점이 있는데, 이 내부에 이 클래스를 위한 기능(로직)을 추가할 수 있다는 것이다. 예를 들어서 유저 이름에 대한 validation이 필요하다면 해당 클래스 내부에 넣으면 된다. 또 이름을 가지고 어떤 계산을 할 기능이 생긴다면, 이 클래스에 추가하면 된다.
밸류 객체의 데이터를 변경할 때는 기존 데이터를 변경하지말고 변경 된 값을 갖는 새로운 밸류 객체를 생성한다. 그러니까 불변 객체로 만드는 것이다. 불변 객체로 만드는 이유는 여러 가지가 있는데, 가장 중요한 이유는 불변 타입을 사용하면 보다 안전한 코드를 작성할 수 있다는 것이다.(불변 타입이 아니라면 Setter를 통해 값을 변경시켜 해당 객체를 참조한 곳에서 예상치 못한 변화가 생길 수 있다.)
DB 테이블의 엔티티와 도메인 모델의 엔티티의 가장 큰 차이점은 도메인 모델의 엔티티는 데이터와 함께 도메인 기능을 함께 제공한다. 단순히 데이터를 담고 있는 데이터 구조라기보다는 데이터와 함께 기능을 제공하는 객체이다. 또 다른 차이점은 도메인 모델의 엔티티는 두 개 이상의 데이터가 개념적으로 하나인 경우 밸류 타입을 이용해서 표현할 수 있다는 것이다.
참고자료 (DDD)
- DDD Start! - 최범균 저
01/14
Javascript 기본
const
const는 재할당이 안된다.
기본 원칙을 다음과 같이 가져가자.
- const를 기본으로 쓴다.
- 그런데 변화가 생길 변수는 let을 쓴다.
- var는 쓰지 않는다.
그러나 const여도 배열과 오브젝트의 값을 변경하는 것은 가능하다.
const list = ["apple", "orange"];
list.push("banana");
console.log(list);
// 그러면 immutable array를 어떻게 만들까?
const list = ["apple", "orange"];
list2 = [].concat(list, "banana");
console.log(list === list2); //false;
ES2015 String에 추가된 메서드 - str.startsWith(other), str.endsWith(other), str.includes(other) 추가됨
for of - 순회하기
var data = [1, 2, undefined, NaN, null, ""];
for (let value of data) {
console.log(value);
}
Spread operator
let pre = ["apple", "orange", 100];
let newData = [...pre];
console.log(pre); // ["apㅇple", "orange", 100]
console.log(newData); // ["apple", "orange", 100]
console.log(pre === newData); // false, pre와 newData는 다른 참조
function sum(a, b, c) {
return a + b + c;
}
pre = [100, 200, 300];
console.log(sum.apply(null, pre)); // 600, 컨텍스트를 바꿔가면서 넣어준다.(?)
console.log(sum(...pre)); // 펼쳐져서 a, b, c로 들어간다.
from method
function addMark() {
let newData = [];
for (let i = 0; i < arguments.length; i++) {
newData.push(arguments[i] + "!");
}
console.log(newData);
}
addMark(1,2,3,4,5);
인자를 주지 않아도 arguments를 이용해서 접근할 수 있다. 여기서 arguments는 배열 처럼 생겼지만 실제 배열이 아니다. 그래서 map하는게 안된다.
function addMark() {
let newData = arguments.map(function(value) {
return value + "!";
});
console.log(newData);
}
// 위 메서드는 안된다.
function addMark2() {
let newArray = Array.from(arguments);
let newData = newArray.map(function(value) {
return value + "!";
});
console.log(newData);
}
// 위 방식은 가능
addMark2(1,2,3,4,5);
Object 생성 방식 - ES6
function getObj() {
const name = "crong";
const getName = function() {
return name;
}
const setName = function(newName) {
name = newName;
}
const printName = function() {
console.log(name);
}
return {getName, setName, name}
}
let obj = getObj();
console.log(obj.getName());
참고자료(Javascript)
JWT (JSON Web Token)
JSON Web Token은 다음과 같이 AAAAAAAA.BBBBBBBBB.CCCCCCC 와 같이 세 부분으로 나누어진다.
여기서 AAAAAAAA부분은 JOSE(JSON Object Signing and Encryption) 헤더, JWT Claim set, Signature 이다.
이 토큰을 어떻게 만드는지를 알아본다. RFC7519 - 7.1 Createing a JWT 부분을 보면 다음과 같다.
7.1. Creating a JWT
JWT를 만들기 위해서는 다음과 같은 단계가 수행되어야 한다. 각 스텝의 input, output사이에는 아무련 의존성이 없다.(순서가 중요하지 않다.)
- 원하는 Claim을 포함하는 JWT Claim을 만든다. 공백이 허용되고, 인코딩 전에 명시적으로 정규화 할 필요 없다.
- JWT Claims Set의 UTF-8 형식으로 바꿔라
- 원하는 헤더를 포함하는 JOSE Header를 만든다. JWT는 JWS 나 JWE 스펙을 따라야 한다. 공백이 허용되고, 인코딩 전에 명시적으로 정규화 할 필요 없다.
- JWT가 JWS 냐, JWE에 기반하냐에 따라서 두가지 경우가 있다.
- JWS 기반이면, JWS Payload로 JWS를 만든다. JWS 스펙에 맞게 생성해야한다.
- JWE 기반이라면, JWE를 위해 plaintext로 메세지를 만들어서 JWE로 사용한다. JWE 스펙에 맞게 생성한다.
- 서명 또는 암호화 작업이 수행되면, 메시지를 JWS 또는 JWE로 하고, 해당 단계에서 작성된 새로운 JOSE 헤더에서 “cty”(콘텐츠 유형) 값을 사용하여 3단계로 돌아간다.
- 그렇지 않으면 결과 JWT를 JWS 나 JWE로 리턴한다.
JWS 스펙에 나와있는 토큰의 예시를 살짝 바꿔본 결과는 다음과 같다.
Header
{
"typ":"JWT",
"alg":"HS256"
}
이를 Base64로 인코딩 하면 eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9 이 나온다.
Payload
{
"iss":"martin",
"exp":1300819380,
"http://example.com/is_root":true
}
이를 Base64로 인코딩 하면 eyJpc3MiOiJtYXJ0aW4iLCJleHAiOjEzMDA4MTkzODAsImh0dHA6Ly9leGFtcGxlLmNvbS9pc19yb290Ijp0cnVlfQ 이 나온다.
그리고 마지막 signature에는 위의 Header.Payload를 우리가 지정한 Secret과 SHA-256으로 암호화 해서 base64로 인코딩 한다.
나는 martin이라는 secret을 사용해서 암호화 하니 mSETIt5sw3WXtHnJoczWfZJ0O6hrF6F7jT7QKW0yRXQ와 같은 결과가 나왔다. (jwt.io사이트를 이용했다.)
그러면 최종적으로 위에서 말한 AAAAAAAA.BBBBBBBBB.CCCCCCC 형식의 JWT Token이 만들어진다.(아래와 같음)
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
.
eyJpc3MiOiJtYXJ0aW4iLCJleHAiOjEzMDA4MTkzODAsImh0dHA6Ly9leGFtcGxlLmNvbS9pc19yb290Ijp0cnVlfQ
.
mSETIt5sw3WXtHnJoczWfZJ0O6hrF6F7jT7QKW0yRXQ
jjwt 라이브러리를 활용한 Java코드는 아래와 같다. 상세한 내부 구현은 살펴보지 않아서 정확하게 알지 못하지만, 위 스펙을 따라 구현했을 것으로 예상한다.
public String generateToken(String userId) {
try {
return Jwts.builder()
.setHeaderParam("typ", "JWT")
.setExpiration(new Date(System.currentTimeMillis() + (6 * 60 * 60 * 1000))) // 6 hours
.claim("name", userId)
.claim("scope", "normal")
.signWith(
SignatureAlgorithm.HS256,
genKey())
.compact();
} catch (UnsupportedEncodingException e) {
logger.error("Jwt Exception", e);
throw new JwtGenerateException();
}
}
private byte[] genKey() throws UnsupportedEncodingException {
return SECRET.getBytes(CHARSET);
}
참고자료(JWT)
01/13
NGINX의 HTTP Health Check
Passive Health Checks
NGINX는 실패한 연결을 다시 시도한다. 만약 실패한 연결이 다시 붙지 않으면, NGINX는 해당 서버를 unavailable로 표시하고 해당 서버로 요청을 보내는 것을 일시적으로 멈춘다(다시 active 표시가 될 때까지).
upstream server 아래에 있는 서버들의 설정은 그 옆에 쓰면 된다.(아래 나와있는 것처럼)
fail_timeout – max_fails 를 넘어서 connection에 실패할 때, 서버를 unavailable로 표시해놓는 시간이다. (default는 10초) max_fails – 연결 실패의 최대 숫자이다. 이 카운트를 넘어서면 해당 서버는 unavailable 표시가 된다. (default는 1회)
upstream backend {
server backend1.example.com;
server backend2.example.com max_fails=3 fail_timeout=30s;
}
Active Health Check
NGINX Plus는 주기적으로 upstream server의 헬스 체크를 할 수 있다.(각 서버로 헬스체크 요청을 보내고 맞는 응답이 오는지 검증하는 방식) 아래와 같은 방식으로 사용하면 된다.
server {
location / {
proxy_pass http://backend;
health_check;
}
}
위 예시는 모든 요청을 upstream group인 backend로 보낸다.(health check on) default 설정으로 매 5초마다 NGINX Plus는 “/” 경로로 요청을 보낸다.(backend group안에 있는 서버들) 만약 통신 에러나, 타임아웃이 발생하면(200~399 외의 응답이 오면) health check fail이다. 그러면 server는 unhealthy 표시가 되고, 해당 서버로 요청을 더이상 보내지 않는다.(다음 health check를 통과할 때까지)
아래 설정 처럼 특정 포트로 들어오는 요청만 health check를 할 수도 있다.
server {
location / {
proxy_pass http://backend;
health_check port=8080;
}
}
또 health_check uri=/some/path와 같은 방식으로 특정 경로로 들어오는 요청만 헬스 체크를 할 수도 있다.
그 외에 Custom Condition을 추가할 수도 있다. health_check block 에서 다음과 같이 사용할 수 있다.
http {
#...
match server_ok {
status 200-399;
body !~ "maintenance mode";
}
server {
#...
location / {
proxy_pass http://backend;
health_check match=server_ok;
}
}
}
위에서는 status code가 200-399 사이인지, 그리고 body에 maintenace mode라는게 포함 되어 있지 않다면 server_ok가 통과한다.(health check 성공)
match에서는 status code, 헤더필드, 응답의 body를 체크할 수 있다.
참고자료(NGINX Health Check)
01/11
Red-Black Tree
Java의 HashMap 공부를 하다가, 하나의 해시 버킷에 8개 이상의 Key-Value pair가 들어간다면 트리 구조로 바뀌는 데 이 내부 구현이 Red-Black Tree로 구현 되어 있다고 해서, Red-Black Tree에 대해 알아보았습니다.
Red-Black Tree는 Self-Balanced Binary Search Tree이다. 각 노드는 레드, 블랙 이라는 색깔을 가지고 있다. 그리고 이진 탐색 트리가 가지고 있는 기본적인 특성에 다음과 같은 특성을 가진 트리 구조를 레드 블랙 트리라고 한다.
- 노드는 레드 혹은 블랙 중의 하나이다.
- 루트 노드는 블랙이다.
- 레드 노드의 자식노드 양쪽은 언제나 모두 블랙이다. (즉, 레드 노드는 연달아 나타날 수 없으며, 블랙 노드만이 레드 노드의 부모 노드가 될 수 있다)
- 어떤 노드로부터 시작되어 리프 노드에 도달하는 모든 경로에는 리프 노드를 제외하면 모두 같은 개수의 블랙 노드가 있다.
레드-블랙 트리가 BST 중 하나이기 때문에 단순 Read에서는 BST의 구현을 그대로 사용해도 된다. 하지만 Insert/Delete의 경우에는 단순 BST의 동작을 그대로 구현하면 레드-블랙 트리의 조건을 만족하지 못한다. 그래서 레드-블랙 트리의 특수한 작업들을 해줘야한다.
다음에서 Insert/Delete 과정을 예시를 통해서 설명해본다.
단순히 다음과 같은 Tree가 있다고 생각해보자.
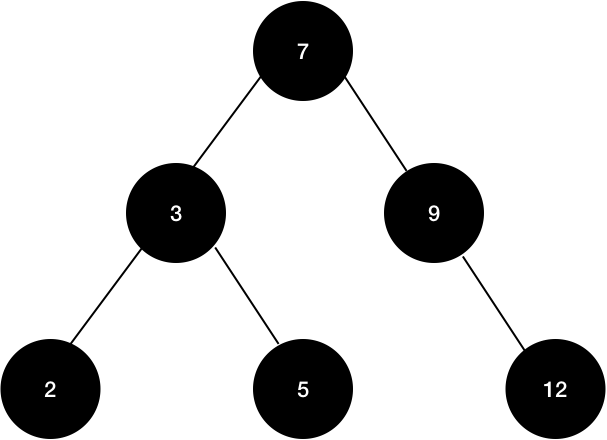
위와 같은 트리를 레드-블랙 트리에 맞게 색을 넣어보면 다음과 같다.
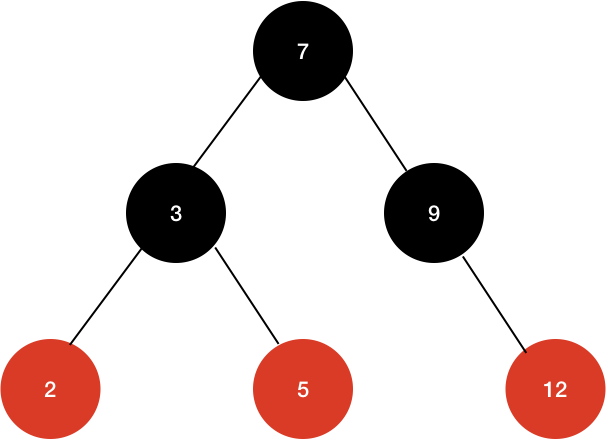
Insert
이 상태에서 4라는 값을 이 트리에 넣어보자. 새로운 값(4)은 일단 파란색으로 표시했다.
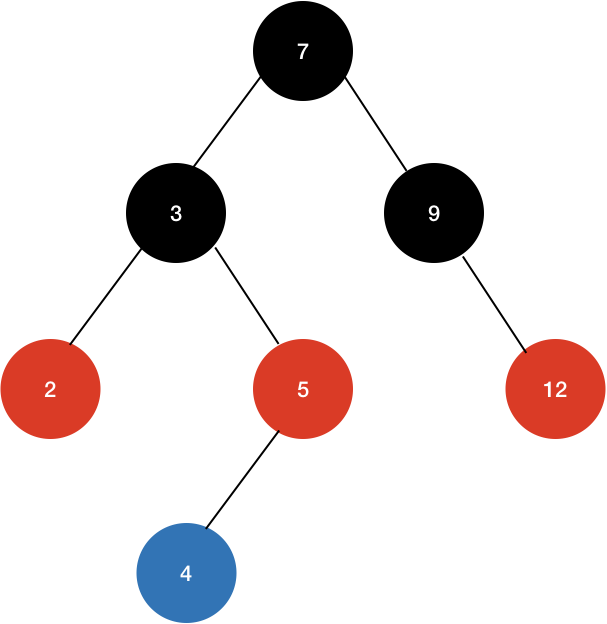
이러면 4는 레드 노드로 일단 들어가게된다.
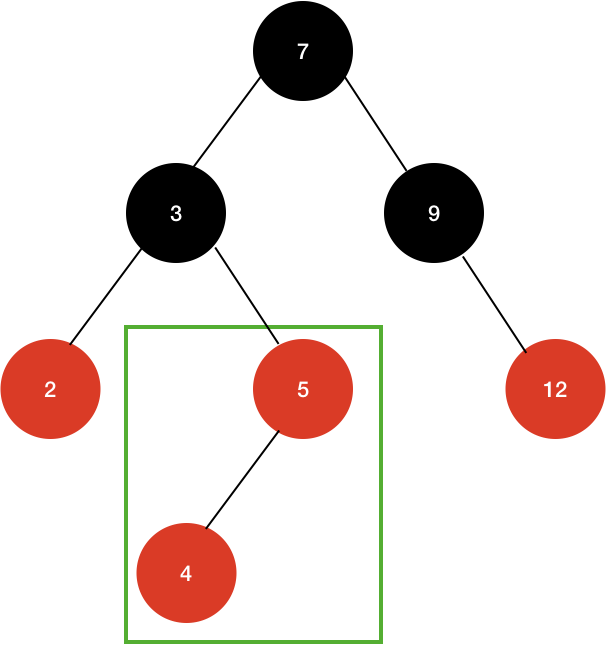
그러면 초록색 박스 부분이 2개의 연속적인 레드가 나타나게 된다. 이 문제를 해결하기 위해서 Uncle Node(부모 노드의 형제)를 살펴봐야 한다.
Uncle Node가 Red면 관련된 노드들의 색을 바꾸는 작업이 필요하다. Uncle Node가 Black이면 노드들의 회전이 필요하다.
Uncle Node - Red인 경우 다음과 같다.
- 삽입 한 노드의 부모, 부모의 형제 노드를 Black으로 바꾼다.
- 삽입 한 노드의 부모의 부모 노드를 Red로 바꾼다.
현재 4를 삽입하는 과정이 위와 같은 경우다. 이를 반영하면 아래 그림처럼 된다.
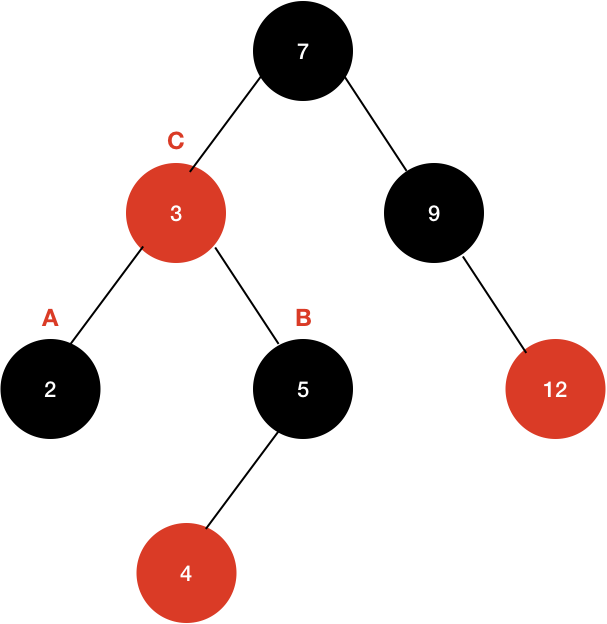
이 경우에 다른 조건들을 만족하는지 확인 하기 위해, 애초에 레드-블랙 트리였으므로 추가된 노드들에 대해 검사해보면 된다. 그러면 A, B 노드가 Black으로 바뀌고 C노드가 Red로 바뀌면서 전체 Black의 개수는 변화가 없는 것을 확인할 수 있다. 여기서 C노드가 Root 노드 였다면 Root는 항상 Black 이어야 하므로 다시 Black으로 바뀐다. 그러므로 Root로부터 나가는 전체 Black 노드의 개수가 1개 늘어났을 뿐 동일하게 늘어났기 때문에, 4번 조건이 항상 만족된다.
이 상황에서 uncle node가 black인 경우를 확인하기 위해 위 트리에 13이라는 값을 추가해보자.
Uncle Node - Black인 경우 다음과 같다.
- 삽입 한 노드와 그 부모, 부모의 부모까지를 오름차순으로 정렬한다.
- 가운데 값을 부모로 하는 트리 형태로 만든다.
- 부모는 Black, 자식들은 Red로 설정한다.
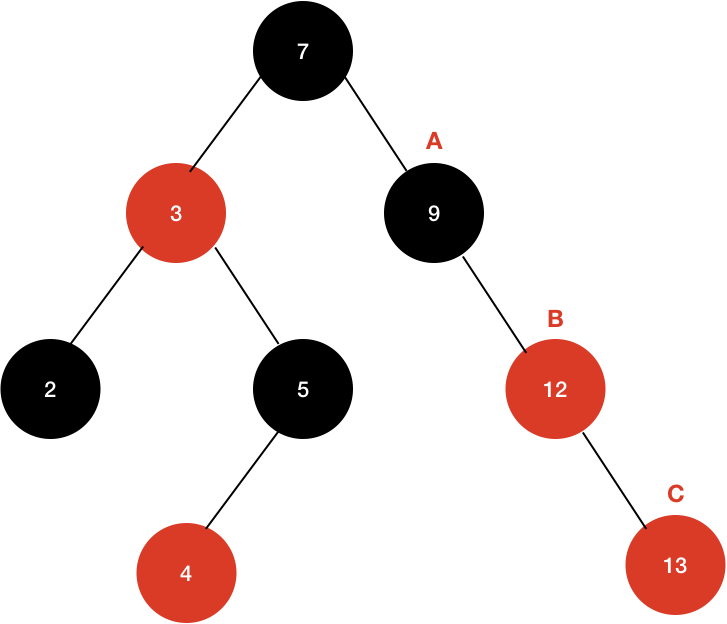
이 상태에서 순서대로 진행 해보면 다음과 같이 변한다.
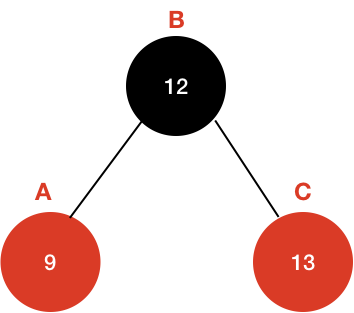
이 노드를 그대로 붙여보면 다음과 같이 변한다.
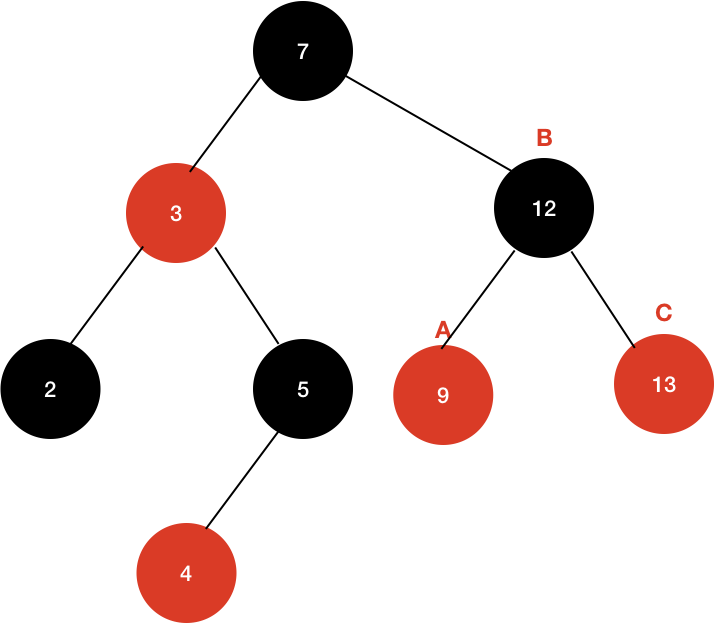
이 경우에도 Black 노드의 개수가 차이가 없기 때문에, 4번 조건이 항상 만족된다.
Delete
삭제를 할 때 모든 경우의 수를 따져보면 다음과 같다.
- 삭제할 노드가 Red
- 자식 노드가 Black
- 삭제할 노드가 Black
- 자식 노드가 Black
- 자식 노드가 Red
먼저 삭제할 노드가 Red, 자식 노드가 Black 인 경우에는
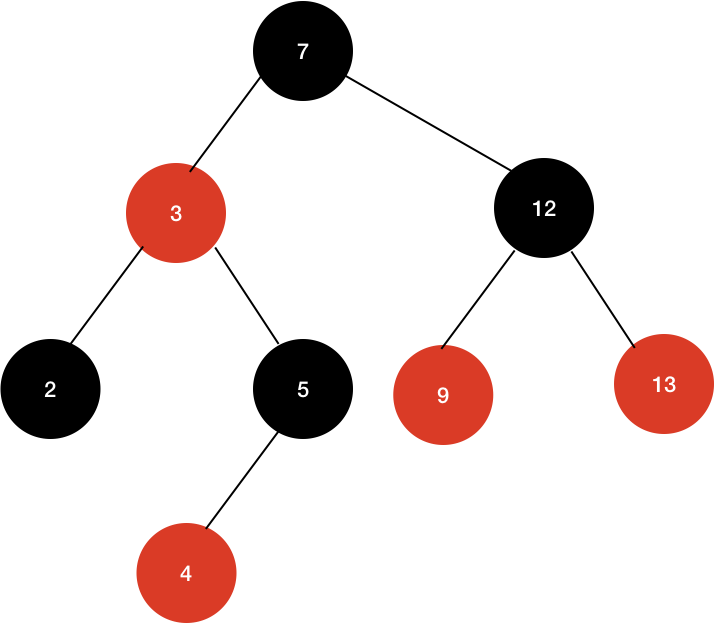
위와 같은 상황에서 3을 제거한다고 생각해보자.
- 3을 지우기 위해 3의 왼쪽 자식 노드 중 가장 큰 값을 찾는다. (2)
- 2 노드를 복사한다.(3 자리로)
- 기존 2 노드를 제거한다.
- 트리의 균형을 맞춘다.
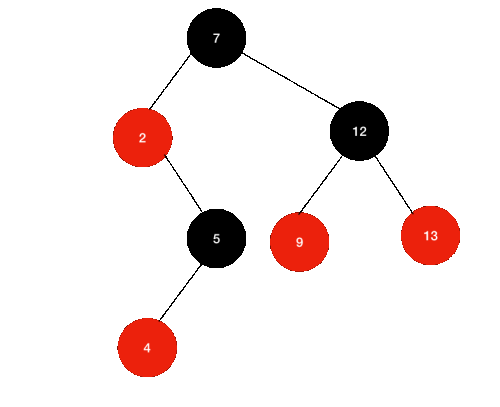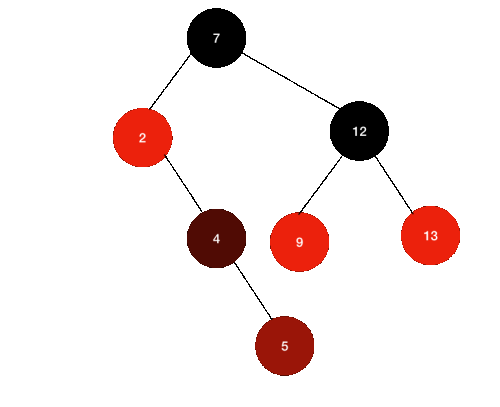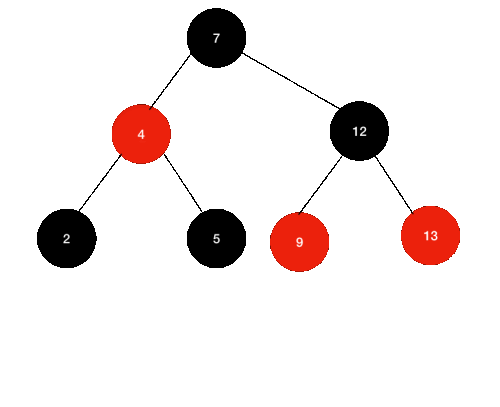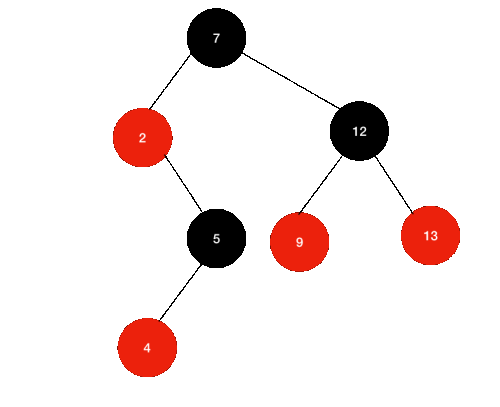
삭제할 노드가 Black, 자식 노드가 Red는 더 어렵지 않다.
위와 같은 상황에서 12를 제거한다고 해보자.
- 일단 12를 찾는다.
- 12의 왼쪽 자식 노드 중 최대값(9)을 찾는다.
- 9 노드를 12의 자리로 복사한다.
- 기존 9노드를 제거한다.
문제가 되는 경우는 삭제할 노드가 Black, 자식 노드도 Black 인 경우이다.
- 삭제할 노드의 형제 노드가 Red
- 형제 노드를 Black으로 바꿈
- 형제 노드가 Black, 형제 노드의 자식이 모두 Black
- 형제 노드를 Red로 변경, 그러면 이 두 형제들을 가진 부모에서 블랙노드가 전체적으로 하나씩 모자라게 된다. 더 커진 트리에서 재귀적으로 해결한다.(이 부모의 형제 노드를 살펴본다.)
- 형제 노드가 Black, 형제의 왼쪽 자식 - Red, 오른쪽 자식 - Black
- 형제 노드를 Red로, 형제 노드를 기준으로 오른쪽으로 회전시킨다.
- 형제 노드(S)가 Black, 형제의 왼쪽 자식 - Red/Black, 오른쪽 자식 - Red
- 부모 노드(R)를 기준으로 왼쪽으로 회전 시킨다, R과 S의 색을 바꾼다. 원래 오른쪽 자식(Red였던)의 색을 Black으로 바꾼다.
댓글남기기