TIL(2월) - 1
틀린 내용이나 본문의 내용과 다른 의견이 있으시면 댓글로 남겨주세요!
02/28
최소값을 구할 수 있는 메서드가 있는 Stack
기본적인 push, pop 기능이 구현된 스택에서 최소값을 반환하는 min 함수를 추가하려고 하는데, 이를 구현해보자. push와 pop 연산은 O(1)에 동작해야 한다. 스택에는 Integer 값이 연속적으로 들어가고, 중복된 값이 들어갈 수도 있다.
public class MinStack extends Stack {
Stack min;
public MinStack() {
min = new Stack();
}
public void push(int value) {
if (value <= getMin()) {
min.push(value);
} else {
min.push(min.peek());
}
super.push(value);
}
public int pop() {
if (super.peek())
min.pop();
return super.pop();
}
public int getMin() {
if (min.isEmpty()) {
throw new EmptyStackException();
}
return min.peek();
}
}
push(int value) 메서드에서 Min Stack에 push를 하는데, 새로 넣을 값이 기존 최소값보다 작으면 새로운 값을 min stack에 넣고, 기존 최소값이 더 작으면 기존 최소값을 그대로 min stack에 넣는다. 그래서 min stack에서는 어떤 상황에서도 최소 값을 peek() 메서드로 O(1)로 꺼낼 수 있다.
방금 머리 속에 있는 내용을 대충 pseudo code로 작성하다보니 틀린 내용이 있을 수 있다.
02/25
시간복잡도
public void foo(int[] input) {
int sum = 0;
for (int i = 0; i < input.length; i++) {
sum += input[i];
}
}
위와 같은 코드에서는 O(N)이다.
public void foo(int[] input) {
int sum = 0;
for (int i = 0; i < input.length; i++) {
for (int j = i + 1; j < input.length; j++) {
System.out.println(input[i] + ", " + input[j]);
}
}
}
위 코드에서는 i는 0 ~ N - 1의 총 N개, j는 i가 0일 때 1 ~ (N - 1), i가 (N - 2)일 때 1개로 총 1개부터 (N - 1)개 까지의 합인 (N - 1)(N - 2)/2개이므로 O(N^2)이다.
public int sum(Node node) {
if (node == null) {
return 0;
}
return sum(node.left) + node.value + sum(node.right);
}
Balanced Binary Search Tree라고 한다면, 위와 같은 코드의 모든 노드를 더하는 것의 시간복잡도를 구해보자.
일단 재귀함수에 분기가 2개 존재하므로 O(2^N)이다. 그러나 이 분기의 N은 이 Balanced Binary Search Tree의 높이인 logN이다. 그래서 O(2^logN)이 되는데, 이는 O(N)이 된다.
참고자료(시간 복잡도)
- 코딩인터뷰 완전분석
02/22
Database Connection Pool
DB와 연결하는 커넥션을 미리 생성 - Pool에 저장 - 필요할때 꺼내쓰고, 사용한 후에는 풀에 반환한다. (멀티쓰레드의 쓰레드풀과 유사)
커넥션을 먼저 생성해두기 때문에 클라이언트가 DB를 사용할 때 생성하는 것보다 빠른 속도를 보장할 수 있다. 또 커넥션의 최대 생성 갯수도 제어할 수 있다. 그래서 사용자가 몰렸을 때, 과부하를 방지할 수 있다.
커넥션의 최대 생성 갯수만큼 연결되었다면, 그 이상의 커넥션에서는 커넥션을 반납 받을 때까지 커넥션을 연결하지 못하고 기다려야 한다.
02/19
CQRS (Command Query Responsibility Segregation)
명령과 쿼리의 역할을 분리한다. 말 그대로 시스템에서 명령을 처리하는 책임과 조회를 처리하는 책임을 분리하는 것이 핵심이다.
명령은 시스템의 상태를 변경하는 작업, 조회는 시스템의 상태를 반환하는 작업
모델을 나눈다는 것은 아마 분리된 하드웨어에서 구동 되는 다른 객체 모델, 다른 논리적 프로세스에서 구동되는 것을 보통 의미한다. 웹 예시는 사용자가 쿼리 모델을 사용하여 렌더링된 웹 페이지를 보는 것이 있을 수 있다.
어떤 상태의 변경을 처리를 위해서 별도의 커맨드를 날린다면, 이 변경사항이 반영된 상태를 렌더링 하기 위해 쿼리 모델로 전달 될 것이다.
인-메모리 모델의 경우에는 아마 같은 데이터베이스를 공유할 것이고, 이 경우에 데이터베이스는 커맨드 모델과 쿼리모델의 통신 역할을 할 것이다. 그러나 별도의 데이터베이스를 사용할 수도 있고, 쿼리 쪽 데이터베이스를 효과적으로 Real-time Reporting Database로 만들어야한다. 별도의 데이터베이스 사이에는 어떤 통신 메커니즘이 있어야한다. 두 모델은 별도의 객체 모델이 아닐 수 있고, 동일한 객체가 RDB에서 커맨드와 쿼리의 인터페이스가 다를 수 있다. 보통은 별개의 모델이라고 한다.
CQRS는 일반적으로 다른 아키텍쳐적 패턴과 잘 맞는다.
우리가 CRUD를 통해 상호작용하는 single representation에서 벗어나서 task-based UI로 쉽게 이동할 수 있다.
CQRS는 event-based 프로그래밍 모델과 잘 어울린다. CQRS 시스템이 Event Collaboration과 통신하는 별도의 서비스로 나누어진 것을 흔히 볼 수 있다. 이를 통해 이러한 서비스는 이벤트 소싱에 이점이 있다. 별도의 모델을 갖는 것은 그 모델의 일관성을 유지하는 것이 얼마나 어려운지에 대한 의문을 일으키고, 결국에는 이 일관성을 사용할 가능성을 높인다. 많은 도메인의 경우 업데이트 시에 많은 로직이 필요하므로 쿼리 모델을 단순화하기 위해 EagerReadDerivation을 사용할 수 있다. 쓰기 모델은 모든 업데이트에 대해 이벤트를 생성한다면, 읽기 모델을 EventPosters로 구축할 수 있다.
CQRS는 DDD로부터의 이점을 가지고 있는 복잡한 도메인에 적합하다.
CQRS를 사용하면서 두 가지 이점이 있다.
하나는 몇몇 복잡한 도메인이 더 쉬워질 수 있다는 것이다. 하지만 CQRS에 맞는 도메인은 매우 적다. 그래서 보통은 커맨드와 쿼리 측의 모델을 공유하는 것이 더 쉬울 수 있다. 일치하지 않는 도메인에서 CQRS를 사용하면 복잡성이 가중되어 생산성이 저하되고 위험이 증가할 수 있다.
두번째는 고성능 애플리케이션을 처리하는 것이다. CQRS는 Read/Write 부하를 분리하여 각 부하에 대한 처리를 나누어 준다. 만약 시스템이 Read/Write의 비중이 큰 차이가 있다면 더 좋을 것이고 그렇지 않더라도, 이에 맞게 시스템에 대한 설계를 하면 될 것이다.
그러나 CQRS가 잘 맞지 않는 도메인 모델에서는 복잡성을 더할 수 있고, 생산성이 오히려 떨어질 수 있다.
참고자료 (CQRS)
02/12
JUnit 생명주기
Junit은 메서드 단위 생명 주기를 갖는다. 개별 테스트 메서드의 실행 전에 새로운 인스턴스를 생성한다. 메서드 별 테스트 인스턴스 생명주기는 Junit Jupiter의 default 행동이다.
만약에 Junit jupiter의 모든 테스트 메서드가 같은 테스트 인스턴스에서 수행되기를 원한다면 @TestInstance(Lifecycle.PER_CLASS) 어노테이션을 테스트 클래스에 달면 된다. 이 모드를 사용하면, 테스트 클래스당 하나의 테스트 인스턴스만 생성된다. 그러므로 테스트 메서드들은 인스턴스 변수들에 저장된 상태에 의존하게 되고, @BeforeEach, @AfterEach 메서드의 상태 초기화가 필요하게 된다.
만약 Kotlin으로 테스트를 작성한다면, @BeforeAll, @AfterAll 메서드를 구현하는 것이 더 쉬울 것이다.
기본적으로 Default Test Instance Lifecycle은 PER_METHOD이다. 그러나 전체 테스트 플랜의 수행에서 default를 변경하는 것도 가능하다. junit.jupiter.testinstance.lifecycle.default로 이름이 되어있는 enum 상수들을 설정하는 것으로 가능하다. 그래서 -Djunit.jupiter.testinstance.lifecycle.default=per_class와 같은 방식으로 JVM을 시작할 수 있다. 아니면 src/test/resources 경로에 junit-platform.properties 파일 내에 junit.jupiter.testinstance.lifecycle.default = per_class 같은 내용으로 채워서 default test instance lifecycle을 설정할 수 있다.
참고자료 (Junit 5)
02/11
Spring Interceptor와 Filter
Filter와 Interceptor는 Controller에 요청이 들어오기전에 어떤 처리를 한다는 점에서 비슷하게 생각할 수 있다. 하지만 Filter는 DispatcherServlet 이전에 로직을 수행하고, Interceptor는 Controller 이전에 로직을 수행한다.
Filter가 어느 위치에서 어떤 일을 하는 지는 알겠는데, 좀 더 알아보기 위해서 주석을 읽어보았다. Filter interface의 주석을 보면 아래와 같다.
/**
* <p>A filter is an object that performs
* filtering tasks on either the request to a resource (a servlet or static content), or on the response
* from a resource, or both.</p>
*
* <p>Filters perform filtering in the <code>doFilter</code> method.
* Every Filter has access to a FilterConfig object from which it can obtain
* its initialization parameters, and a reference to the ServletContext which
* it can use, for example, to load resources needed for filtering tasks.
*
* <p>Filters are configured in the deployment descriptor of a web
* application.
*
* <p>Examples that have been identified for this design are:
* <ol>
* <li>Authentication Filters
* <li>Logging and Auditing Filters
* <li>Image conversion Filters
* <li>Data compression Filters
* <li>Encryption Filters
* <li>Tokenizing Filters
* <li>Filters that trigger resource access events
* <li>XSL/T filters
* <li>Mime-type chain Filter
* </ol>
*
* @since Servlet 2.3
*/
public interface Filter {
/**
* <p>Called by the web container
* to indicate to a filter that it is being placed into service.</p>
*
* <p>The servlet container calls the init
* method exactly once after instantiating the filter. The init
* method must complete successfully before the filter is asked to do any
* filtering work.</p>
*
* <p>The web container cannot place the filter into service if the init
* method either</p>
* <ol>
* <li>Throws a ServletException
* <li>Does not return within a time period defined by the web container
* </ol>
*
* @implSpec
* The default implementation takes no action.
*
* @param filterConfig a <code>FilterConfig</code> object containing the
* filter's configuration and initialization parameters
* @throws ServletException if an exception has occurred that interferes with
* the filter's normal operation
*/
default public void init(FilterConfig filterConfig) throws ServletException {}
/**
* The <code>doFilter</code> method of the Filter is called by the
* container each time a request/response pair is passed through the
* chain due to a client request for a resource at the end of the chain.
* The FilterChain passed in to this method allows the Filter to pass
* on the request and response to the next entity in the chain.
*
* <p>A typical implementation of this method would follow the following
* pattern:
* <ol>
* <li>Examine the request
* <li>Optionally wrap the request object with a custom implementation to
* filter content or headers for input filtering
* <li>Optionally wrap the response object with a custom implementation to
* filter content or headers for output filtering
* <li>
* <ul>
* <li><strong>Either</strong> invoke the next entity in the chain
* using the FilterChain object
* (<code>chain.doFilter()</code>),
* <li><strong>or</strong> not pass on the request/response pair to
* the next entity in the filter chain to
* block the request processing
* </ul>
* <li>Directly set headers on the response after invocation of the
* next entity in the filter chain.
* </ol>
*
* @param request the <code>ServletRequest</code> object contains the client's request
* @param response the <code>ServletResponse</code> object contains the filter's response
* @param chain the <code>FilterChain</code> for invoking the next filter or the resource
* @throws IOException if an I/O related error has occurred during the processing
* @throws ServletException if an exception occurs that interferes with the
* filter's normal operation
*
* @see UnavailableException
*/
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain)
throws IOException, ServletException;
필터는 리소스에 대한 요청이나 응답에 대한 필터링을 수행하는 객체이다. 필터는 doFilter() 메서드로 필터링을 수행한다. 모든 필터는 초기화 파라미터를 얻을 수 있는 필터 설정 객체에 대한 접근 권한과 필터링 작업에 필요한 리소스를 로드하는 데 사용할 수 있는 서블릿 컨텍스트에 대한 참조가 있다.
웹 컨테이너에 의해 호출되고 필터로 쓰이고 있음을 표시한다. 서블릿 컨테이너는 필터를 인스턴스화한 후 딱 한 번 init method를 호출한다. Init method는 필터가 필터링 작업을 수행하기 전에 성공적으로 완료 되어야 한다.
doFilter method는 체인의 끝에 있는 자원에 대한 클라이언트의 요청으로 인해 Request/Response pair가 체인을 통과할 때마다 컨테이너에 의해 호출된다. 이 메서드에 도착한 필터 체인은 체인의 다음 엔티티에 요청과 응답을 전달 할 수 있도록 한다. 이 메서드의 일반적인 구현은 아래와 같다.
- Request 검토?
- 입력 필터링을 위한 컨텐츠 또는 헤더를 필터링 하기 위한 커스텀 구현으로 Request 객체 포장
- 출력 필터링을 위한 컨텐츠, 헤더를 필터릴 하기 위한 커스텀 구현으로 Response 객체 포장
FilterChain을 타고 가면서 Request, Response 객체를 커스텀하게 구현하며 변경, 또는 어떤 필터링 기준으로 설정할 수 있는 것으로 보인다.
Filter는 J2EE 표준 스펙의 Servlet 기술 중 하나 이고 Interceptor는 스프링에 있는 영역이다.
02/03
Merge Sort
하나의 리스트를 같은 크기의 부분 리스트로 나누고, 나누어진 부분 리스트를 각각 정렬하고 정렬된 부분 리스트를 합쳐서 전체 리스트를 만든다.
다음과 같은 단계로 이루어진다.
- 분할 - 하나의 리스트를 같은 크기의 2개의 부분 배열로 분할
- 정복 - 부분 배열을 정렬한다. 여기서 재귀적으로 1. 분할, 2. 정복의 방법을 적용한다.
- 결합 - 최종적으로 정렬된 부분 배열을 하나의 배열로 합친다.
전체 N개의 원소를 정렬한다고 했을 때, 한번 나눌 때 N/2가 되어 최종적으로 1개의 원소로 쪼개졌을 때, 맨 마지막 부분 배열의 개수는 N개가 되고 이 N개의 부분 배열을 N/2개의 부분배열로 합치려면, N/2 쌍을 2번씩의 비교가 필요하다. 그 다음은 N/2개의 부분 배열을 합치려면 N/4쌍 리스트를 4번씩 비교를 해야한다. 그래서 한 라인 별로 총 N번의 연산이 필요하고, N~1 까지 2로 나눈 리스트를 만드는 경우에 전체 이진 트리의 높이는 logN이기 때문에, 결국 최종적으로 시간 복잡도는 O(nlogn)이다.
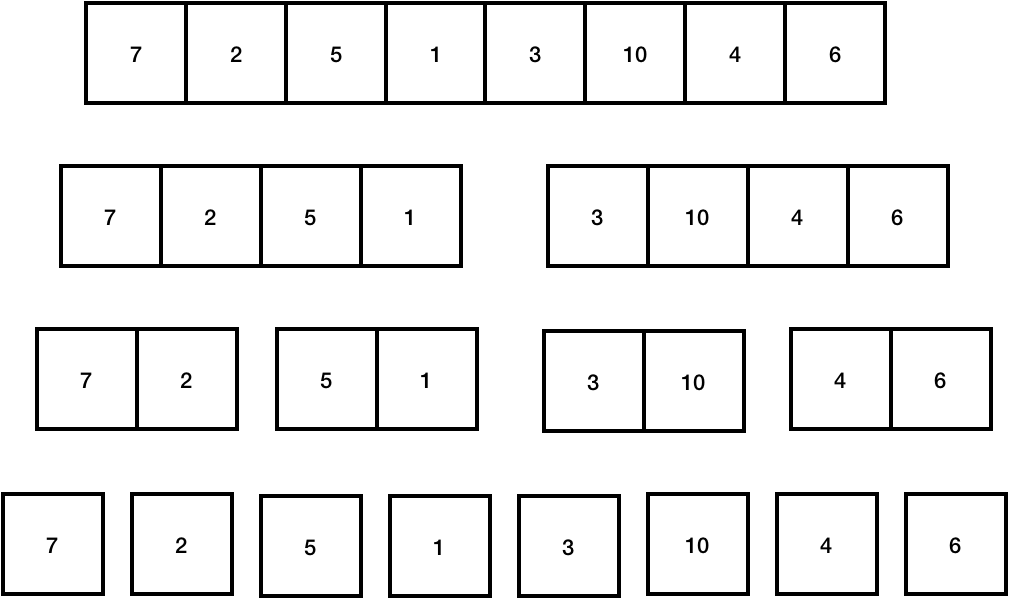
위와 같은 방식으로 간단하게 부분 배열로 나눈다. 최종적으로 크기가 1인 배열이 되면 그만 나눈다.
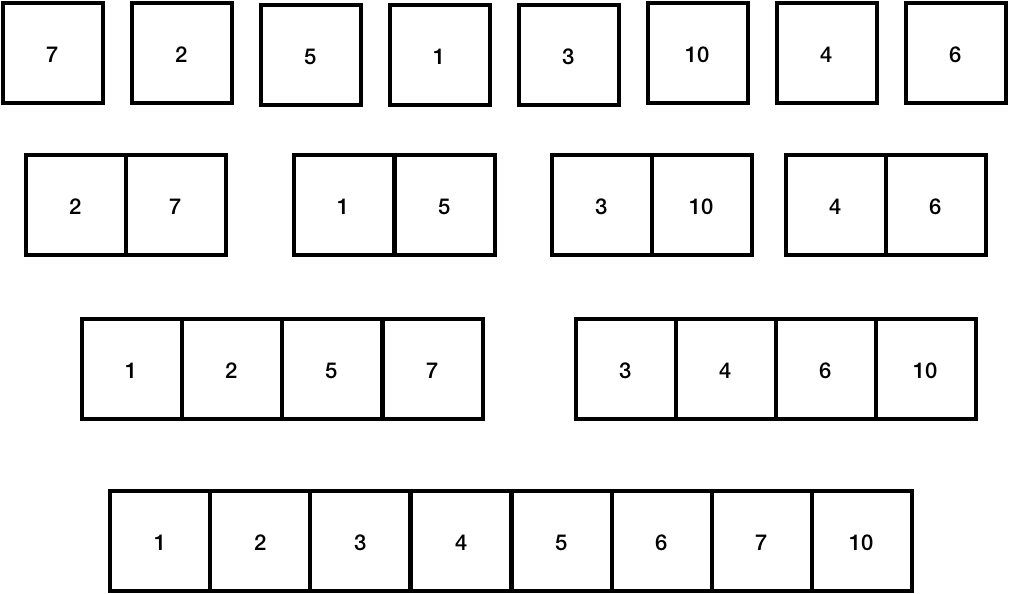
나누어진 상태에서 각 배열을 합치면서, 배열의 값들을 비교하며 크기별로 정렬한다. 위 그림에서 두번째 줄을 보면, 8개의 부분 배열을 합치며 총 4쌍의 부분 배열이 만들어지고, 2번씩의 비교가 필요해 총 8번의 연산이 필요한 것을 볼 수 있다. 세번째 줄을 보면, 4개의 부분 배열을 합치면서 총 2쌍의 부분 배열(1,2,5,7 / 3,4,6,10)이 만들어지고, 만들기 위해 총 4번 씩의 비교가 필요해서 결과적으로 총 8번의 연산이 필요한 것을 알 수 있다. 그리고 이 구조를 이진 트리라고 생각할 수 있으므로, 이 트리의 높이는 logN으로 최종적으로 머지소트의 시간복잡도는 O(NlogN)이다.(worst, best, average case 모두)
아래는 머지소트를 간단하게 구현해 본 내용이다.
void mergeSort(int a[], int n){
if(n == 1){
return;
}
int i,j,k;
int tArr[n];
int m = n / 2;
mergeSort(a, m);
mergeSort(a + m, n - m);
i = 0;
j = m;
k = 0;
while (i < m && j < n) {
tArr[k++] = a[i] < a[j] ? a[i++] : a[j++];
}
while (i < m) {
tArr[k++] = a[i++];
}
while (j < n) {
tArr[k++] = a[j++];
}
for(i = 0; i < n ; i++){
a[i] = tArr[i];
}
}
02/02
PCB (Process Control Block)
말 그대로, 프로세스를 관리하기 위한 OS의 자료구조이다. 그렇기 때문에, 프로세스를 관리하는데 있어 필요한 정보들이 담겨져 있다.
여기서 프로세스의 위키 내용을 보면 아래와 같다.
프로세스(process)는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 말한다. 종종 스케줄링의 대상이 되는 작업(task)이라는 용어와 거의 같은 의미로 쓰인다. 여러 개의 프로세서를 사용하는 것을 멀티프로세싱이라고 하며 같은 시간에 여러 개의 프로그램을 띄우는 시분할 방식을 멀티태스킹이라고 한다. 프로세스 관리는 운영 체제의 중요한 부분이 되었다.
정리 해보면
- 실행중인 프로그램
- 커널에 의해 관리되고 등록된 엔티티
- 시스템 자원을 사용하고, 요청할 수 있게 허가된 엔티티
- PCB에 할당된 엔티티
PCB는 프로세스를 관리하기 위한 자료구조고, 프로세스는 PCB에 할당된 엔티티라고 하니까 좀 순환참조 느낌이다.
PCB는 일단 아래와 같은 구조로 되어있다.

OS 마다 PCB는 다른 구조를 가질 것이다. PCB는 Process ID라는 고유한 값으로 구분되고, 프로세스의 라이프 타임 동안 유지되며, 프로세스가 종료되면 사라진다.
참고자료(PCB)
Context Switching
말 그대로 현재 실행중인 프로세스를 멈추고, Context를 Switching 한다. 현재 실행중인 프로세스를 멈추려면 실행중인 프로세스의 정보를 저장해두어야 한다. 프로세스에 대한 정보는 PCB에 있다. Ready 상태인 프로세스와 Running 상태인 프로세스가 인터럽트에 의해 서로 상태가 transition된다.
컨텍스트 스위칭은 CPU에 많은 부하를 가져다 준다. 컨텍스트 스위칭이 일어나는 동안 CPU는 아무런 일도 하지 못한다. 커널은 Ready 상태로 돌아가는 프로세스의 정보를 PCB에 저장하고 Running 상태로 들어갈 프로세스의 Context를 CPU에 적재한다.
Context Switching 비용은 Process가 Thread보다 많이 든다. 그 이유는 Thread는 Stack을 제외한 Code, Data 영역은 다른 쓰레드에서도 공유하기 때문에 이 부분은 컨텍스트 스위칭에 들어가지 않는다.
댓글남기기